論文紹介: An evaluation of distributed concurrency control
書いた人 : @nikezono
TL;DR
- 分散DBでSerializableで,Writeを扱うのはなかなか無理筋である
- Read-Onlyならスケールする
- 一台だけConcurrencyを扱う専門のサーバを用意する手法が性能が落ちにくく良い
- が,その一台がボトルネックになる
- 光速がもっと早くならない限り,データモデリングとかプログラミングパラダイムから考えなおさないと厳しい
(私の感想です)
概要と紹介理由
トランザクション処理の重要性は依然として変わらず,その性能要求だけが日に日に高まっている.
これは現代の分散コンピューティングのトレンドとあいまって,分散トランザクション(distributed transaction) という概念を生んだ.
たとえば,データを複数のサーバに分割(Partitioning)すれば,各サーバは並列でリクエストを処理できる.
しかし,このとき,複数のサーバにまたがる(across-partition)リクエストが来てしまうと,一般に処理性能はむしろ落ちてしまう.
分散トランザクションの実装には,並列性を高めつつ,across-partitionのリクエストをより高速に処理することが求められる.この Distributed Concurrency Control の実装には多くの手法が存在する.この論文では, これらの手法を横断的に比較できるる分散データベース Deneva を開発し,評価を行っている.
結論として,分散トランザクションのアルゴリズムは,アプリケーションレベルのデータモデリングと,DC内のネットワークに用いるハードウェアと密結合することが重要である とされた.
Reference
Rachael Harding, Dana Van Aken, Andrew Pavlo, and Michael Stonebraker. 2017.
An evaluation of distributed concurrency control.
Proc. VLDB Endow. 10, 5 (January 2017), 553-564.
DOI: https://doi.org/10.14778/3055540.3055548
1. Introduction
Data generation and query volumes are outpacing the capacity of single-server database management systems(DBMS).
現代のデータ量とクエリ量は,単一サーバのDBMSが捌ききれる処理能力を既に凌駕している.
となれば並列化をするしかない……すなわち,分散データベース,分散トランザクションという話になる.
全てのリクエストに対して完璧にパーティションできればーつまり,パーティションをまたいだデータ取得がなければー無限に並列性を出せるわけだが,一般にそれは難しい.
SELECT COUNT(*) FROM table;
というクエリが,既にキャッシュしてある統計情報にヒットするだけで済んでくれればいいが,最悪の場合全パーティションから合算を行うことになるかもしれない.大陸間,惑星間でデータベースを分散している場合,こういうクエリはかなり厳しくなる.全てのサーバの計算を集約する必要があるからだ.これでは分散データベースはいたずらに性能を落とすだけになる.
この論文では, Deneva というフレームワークを用いて分散トランザクションの実装を定量的に評価している.
ここでは詳しく説明しないが,分散トランザクションには一貫性や分離性に関するいくつかの分類があり,たとえばEventual consistencyであるとか,Linearizableとか,色々ある.このDenevaでは,そのうち Serializable を念頭に置いている.
参考までにPeter Bailis御大による分類図を貼っておく.
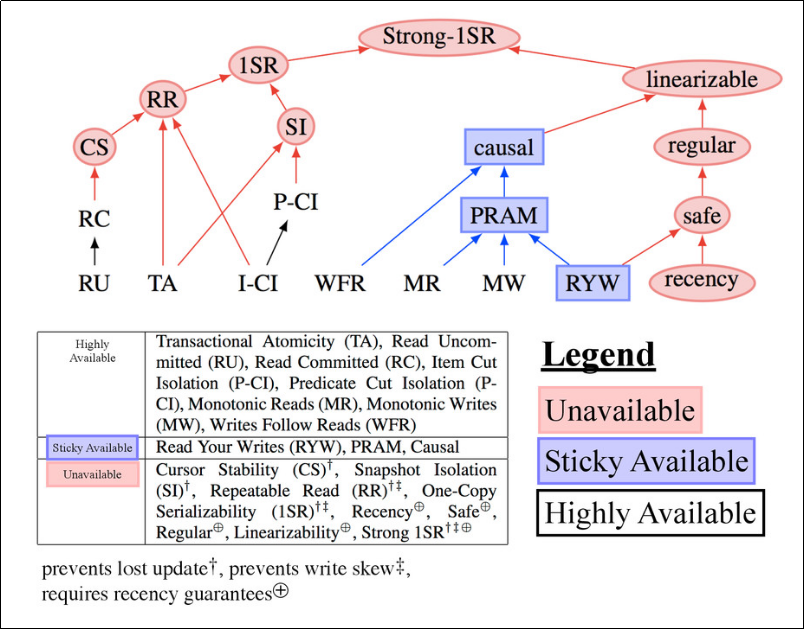
Peter Bailis, Aaron Davidson, Alan Fekete, Ali Ghodsi, Joseph M. Hellerstein, and Ion Stoica. 2013. Highly available transactions: virtues and limitations. Proc. VLDB Endow. 7, 3 (November 2013), 181-192. DOI=http://dx.doi.org/10.14778/2732232.2732237
このように分散トランザクションの実装の分類は非常にややこしいことになっているのだが,Denevaはこの図中でもっとも上位に位置し,最も強い制約を強いる Strong-1SR を前提にして評価している.(おそらく.文中の記述からは1SRの可能性もあるが,1SRのみの分散トランザクションはかなり大胆でユーザに不便な最適化も許すので,ここではStrong-1SRと考えるのが自然)
2. SYSTEM OVERVIEW
Denevaのアーキテクチャは以下.
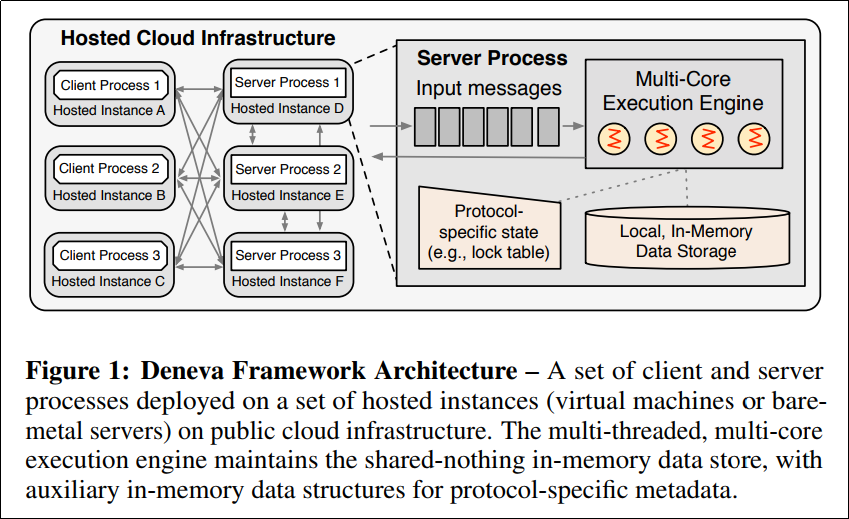
インメモリDBがあって,分散トランザクションのためのエンジンがその上に載っている,というシンプルな構成.
全てのトランザクションはストアドプロシージャとして実装される.つまりプリコンパイルされており,SQLパーサやプランナ,オプティマイザ等のオーバヘッドは一切ないものである.予め,データベースに対するクエリをストアドプロシージャにコンパイルすることで,あらゆるクエリは read か update ,その組み合わせに変換される.
また,全てのクライアントとサーバはフルメッシュで繋がっており,TCP/IPをプロトコルとして用いている.サーバはConsistent Hashingによって配置され,クライアントは各サーバのパーティション情報を共有している.
後は少々割愛するが,サーバ側はトランザクションがアボートした際は10ms後に再実行するとか,優先度付きキューにリクエストを貯めていくとか,ノードIdとスレッドIdを用いて分散タイムスタンプを作る,といった詳細が書いてある.興味がある方は読むといいが,それほど面白いことは書いていない.
3. Transaction Protocols
比較実験するstate-of-the-art protocolsは6手法. それぞれを紹介し,簡単に説明する.
3.1 Two-Phase Locking
二相ロックとして知られる.トランザクションを成長層と縮退層に分割し,成長層ではロックの獲得 のみ を,縮退層ではロックの解放 のみ を行う.全てのロックを獲得している間,他の競合するトランザクションに対して完全に排他できることが証明されている.競合に対して排他できるということは,直列実行と等価にできる,ということである(== Serializable).
なぜ排他できるのか,ということが直感的にわかりやすい.
https://qiita.com/kumagi/items/d3c671ddd1aa5648dd91
歴史は古いが,既存のトランザクション手法の多くがこの手法をベースラインとしている.
問題はデッドロックが起こりうることで,デッドロックを回避する方法によって手法が細分化される.
そこは割愛するが,ここでは NO_WAIT と WAIT_DIE という手法が実装されている.
このプロトコルのキモは,ロックの獲得と解放にある.分散トランザクションにおいては,リモートのサーバのデータをロックするコストは高くつくと想定される.
3.2 Timestamp Ordering
全トランザクションに,一意かつ単調増加するタイムスタンプを付与し,このタイムスタンプ順にトランザクションが起こった/起こるとみなして処理をさせる.タイムスタンプと矛盾するread/updateをすることになりそうなら,アボートする,というプロトコル.
たとえば,
key: writer
x: t1
y: t4
のとき,
Transaction 3: update(x), read(y)
はアボートされる.update(x) は問題なさそうだが, read(y) でTransaction 4の書いた値を読むのはおかしいからだ.
このプロトコルはシンプルに記述でき,かつデッドロックも回避できる.だいたい二行に落ちる:
- タプルのwrite timestamp <= 自分のtimestampのとき,read可能
- タプルのread/write timestamp <= 自分のtimestamp のとき, write可能
上述した例はシンプルなKVSのようなものを想定したものだが,PostgreSQLやMySQL, Oracleのように,Multiversion Concurrency Control(MVCC) を採用しているデータベースも存在する.これらのデータベースは,
x: t0->t1
y: t0->t1->t2->t4
といった風に,複数のバージョンのupdateを記録できる.となると,先ほどの read(y)も t2の書いたものを返せば良さそうである.DenevaではMVCCにおけるTimestamp Ordering(すなわちMVTO)も実装している.
3.3 Optimistic
Optimistic Concurrency Control(OCC)は,コミット直前までread/writeを反映せず,ロックも獲得せず,あらゆる調停をやらない,というアプローチだ.
これを実装する場合往々にしてバージョン情報など追加の情報がデータベースに必要となるが,恩恵は大きい.
結局アボートするトランザクションのwriteは無駄になるし,元の値を書きなおさないといけない.もちろんロックも無駄になる.それに,ユーザから与えられたクエリの中に,
update(x)
sleep_or_something_heavy_task(1Hour)
commit()
という風にカジュアルに重いタスクが入っていたら,その間 x のロックは取りっぱなしになる.
このようなオーバーヘッドを排除するため,極力Optimisticにロジックを進行させるのがOCCである.
OCCには様々なVariantがあるが,この論文ではMaaTを採用している.
3.4 Deterministic
ここまでの手法は全て1980年代には登場したものだが,この Deterministic Database という概念はかなり新しい.体系的に論じられはじめたのはこのVLDB2014論文が初出と思われる.
この手法は端的に説明されている:
Centralized coordinators that decide on a deterministic order of the transactions can eliminate the need for coordination between servers required in other concurrency control protocols.
つまり,予め1つのノードをトランザクションの実行順序を決定する仕事の専属として割り振り,以降は決定論的(deterministic)に振る舞うということ.これによって他のプロトコルで語られていたロックやタイムスタンプやアボートといった概念が消滅する.
また,全てのトランザクションが何を読み書きするのか,という情報が既知であるため,同じクエリが再び届いた際には,前のトランザクションの情報をそのまま流用する,などの最適化が可能である.
有名な実装にCalvinがあり,同様のプロトコルがFaunaDBとして市場に出ている.
3.5 Two-Phase commit
CALVIN以外の全てのプロトコルは,2フェーズコミットを用いる.
要するに,あるトランザクションについて,コミットしたのかアボートしたのか,全ノードが合意する必要があって,2PCを使った,ということ.
2PCについては本筋ではないので割愛
4. Evaluation
以下実験設定
- AWS EC2 m4.2xlargeを用いる
- 8コア 32GB memory
- 10000のクライアントを用意し,常にリクエストを流し続ける
- 60秒を暖気に使い,次の60秒でスループット等々を計測
- YCSB, TPC-C,PPS で計測
- YCSB: 1 table(つまりKVS),10 columns(100B char), ~16 million records per partitioning. 各トランザクションは合計10 recordsをread/updateする.(つまりworkload a)
- TPC-C: PaymentとNewOrderをmixしたworkload. Paymentは二つのpartitionに触る. NewOrderは一つだけで,挿入のみ.
- PPS: この論文オリジナル?の部品供給(Product Parts Supplier)ワークロード.
4.2 Contention, 4.3 Update rate
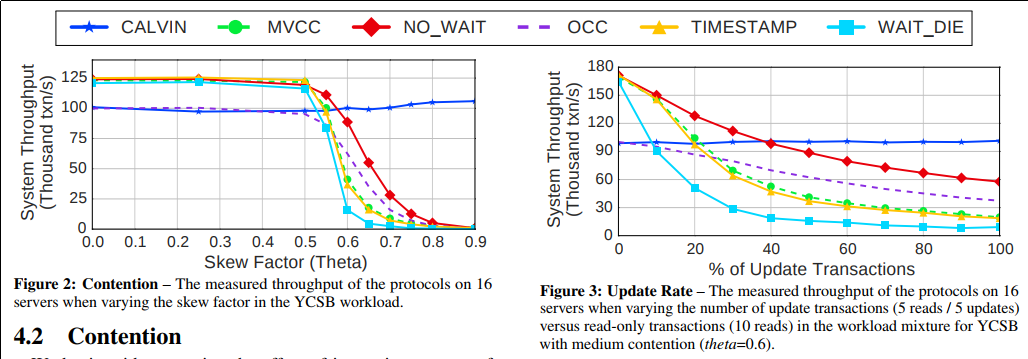
Figure.2はYCSB WorkloadにおいてContention Rateを上げていった際のグラフである.
Contention Rateはすなわち競合の割合で,同じデータにアクセスする割合を意味する.詳しくはYCSBの記事を参照のこと.
図を見てわかるように,競合の割合が少ない場合は,ロックやタイムスタンプといった実装による性能差はたいしてない.
が,競合が増えてくるとDeterministic Database(CALVIN)が強くなってくる.1ノードで全てのリクエストを一度順序付けする関係上,競合が少ない場合はそこがボトルネックになってしまうのだが,競合が多い場合でも,他のワーカーノードが一切メッセージングを行わなくてよいことから,性能が落ちない.むしろ,同じデータを参照することが多い,ということは,前のトランザクション結果の再利用性が高まることから,少し性能が向上している.
Figure.3 はYCSB Workloadにおいてupdateの割合を上げていった際のグラフである.
10 readsから10 updatesまで,read/updateの命令の割合を変えていくと,性能はこのように変化する.
2PLのNO_WAITが性能が高く,WAIT_DIEはupdate rateが低い段階から性能が落ち込む.これはロックが競合した際の挙動によるもので,NO_WAITは単にアボートする単純なプロトコルなのだが,そのぶんオーバーヘッドが少ないようだ.
そして,やはりこのワークロードでもCALVINが安定している.read-only(10 reads)でもwrite-only(10 writes)でも全く変わらない性能を示している.通常,readはコピーで済むがwriteはデータベースへの書込みやログを伴うため,writeの割合が増えれば性能が落ちるのが自然である.CALVINがそうならない理由は,最初の決定論的な実行順序の決定の段階で,全てのノードの仕事を決定して,以降ノード間の通信を行わないことにある.これによって並列性が保たれる,ということらしい.
(だが,それにしたって書込みは読み込みより遅いはずで,こうまで性能が変わらないのは違和感がある.Figure 2ともほぼ同じ性能を示していることから,CALVINには他にボトルネックがあるのかもしれない)
4.5 Scalability
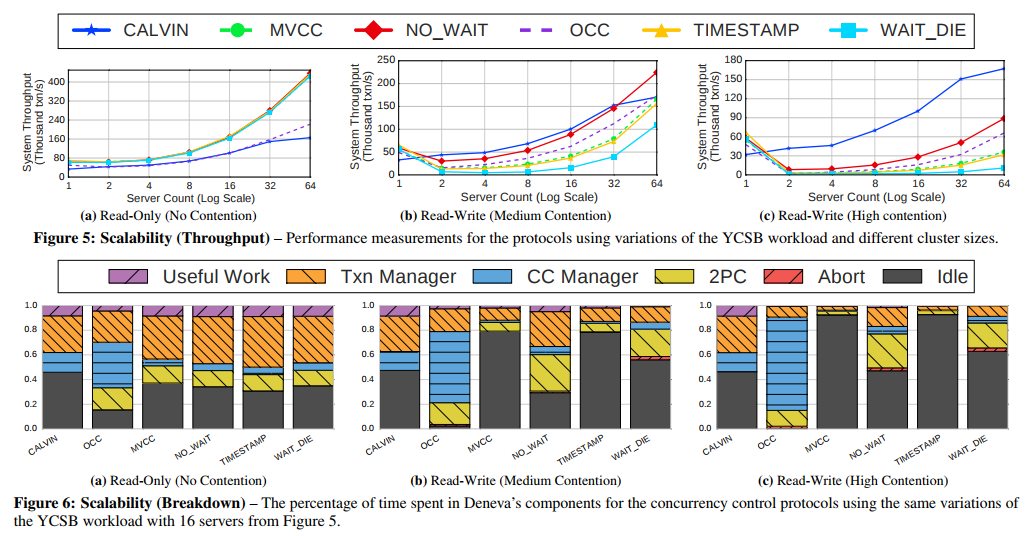
Figure 5は先ほどと同じくYCSB Workloadを実行し,Contention RateとUpdate Rateをそれぞれ固定し,サーバ台数を増やした実験である.Figure 6ではサーバ台数16台の際の各手法における処理時間の内訳を集計している.
Figure 5は(a)(b)(c)とUpdate RateとContention Rateを変えて実験しているが,先ほどの実験から見て取れるように,contention rateが高くなるとCALVINが一人勝ちの様相を呈する.それぞれの手法の処理時間の内訳をFigure 6で見てみると,(OCCは除いて)CALVINに対して他の手法は 2PC の処理時間の比率が高い.
すなわちサーバ間のメッセージングか,他のサーバのトランザクションの処理待ち,といった要素が支配項になっている.これを排することができるCALVINがContention Rateが高い際に一人勝ちする.
ただし,Contention Rateが低い,Read-OnlyのFigure 6(a)を見ると,逆に,Calvinが最も idle の時間が多いことがわかる.これは1つのサーバに決定論的なスケジュール生成を全て任せていることに起因する.
4.6 Network latency
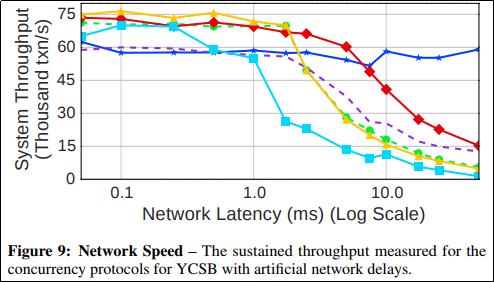
Figure 9はネットワークのレイテンシが高まった際の性能劣化を見ている.CALVIN以外の手法は,ロックやタイムスタンプ等,何かしらのやり方でサーバ間のメッセージングを行っているから,レイテンシが増えるにつれ性能が一気に落ち込んでいく.
5. Discussion
分散DBのボトルネックについてこの論文では調査してきたが,以下が言えそうだ.
Foremost is that the commit protocol is one of the primary
factors that affects throughput. Most of the protocols require two
round trips before committing.
多くのプロトコルは2ラウンドトリップがコミットのために必要(Denevaの場合2PC)であり,これがボトルネックになる.CALVINはそれを除去しているのが強い.
Another major bottleneck for distributed DBMSs is data contention
due to two major factors.
他の分散DBMSのボトルネックとしては,Contentionについて二つある.
First, there is no contention without
record updates. When we varied the update rate in the YCSB workload,
we found that when there were few updates using a protocol
with minimal overhead, such as 2PL or a timestamp protocol, made
the most sense.
まずひとつは,update rateが増えてこないうちは,in-placeに読み書きできる2PLやTimestampが強いのだが,updateが増えてくると,他のサーバとのメッセージングによる調停が必要となってきて,しまいにはDeterministicに負けるということ.
Second, the frequency of
reads and updates to hot records determines how often contention
occurs.
次に,Hot Recordの存在.多くのトランザクションが触りに行くHot Recordがあると,ロック期間の長さやアボートの回数が足を引っ張るということ.2PLやTimestampは実装の軽量さから最初は性能が良いが,Hot Recordがあるとこの要因から性能が落ち,やはりDeterministic Databaseに勝てない.
これらのボトルネックを除去するため,以下のアプローチが必要だ,とこの論文では提唱している:
- Improve the Network.
- DC内部でのネットワークをより高速なものにするとか,RDMAを用いるといった工夫を行うなど.
-
a 5μs message delay admits considerabley more parallelism than the ~500μs delays we experience on cloud infrastracture today.
- とくに,地理分散DBとなるとレイテンシが命となる.が,光速は変えられないので…
- Adapt the Data model.
- 単一ノードでトランザクションが簡潔するように,データモデリングを変える.
- 現在のリレーショナルデータモデリングでは,水平/垂直分割といったアプローチになるが,これはノードまたぎを起こしやすい.
- たとえば太古の階層型データモデリングとか,そういったものを使って色々と考えなおす.
- Seek Alternative Programming Models:
- 先ほど見たPeter Bailis御大の図にあるように,そもそもSerializableにすることが分散トランザクションのオーバーヘッドの原因の大半だ.
- であるから,Eventual consistencyでいいところはそうするとか,妥協を許せるところは許せば性能は上がっていく.
- しかし,それでSerializableで防げていたバグが出てしまうのは困る.
- 新しいプログラミングモデルでカバーできるとよい.
- このへんは前にブログで書いた
結論&感想
至極当然の結論として, SerializableにWriteするのは分散システムでは厳しい ということが導かれたように思う.
一見して性能が良いように見えるDeterministic Databaseがとっているのは,Concurrency Control部分をすべて1台のサーバに移譲するアプローチだ.
これでは1台のサーバ性能が頭打ちになっている,という問題に回答できているわけではない.
ネットワークの性能向上にもいつしか限界があるから,並列化による性能向上の恩恵を受けたければ, 同期やロックを限界までなくす しかない.
となればプログラミングパラダイムから考えなおしましょう… というのは,筋のいい話だ.
この論文自体は,ベンチマーク論文であり,わりと実装力に任せて書かれたものだと思うが,上記のような最近のトレンドに説得力を持たせるという意味では,良い論文だった.