論文紹介: An empirical evaluation of in-memory multi-version concurrency control
書いた人: @nikezono
追記
この解説記事はあまりに内容が粗雑だった.
別の機会に作成したスライドを貼っておく.
これを読めばこの記事の本文を読む必要はそれほどない.
(そもそも論文を読めば解説記事など読む必要はないのだが)
要約
マルチバージョン同時実行制御(MVCC) は昨今のDBMSにおいて最も使われている同時実行制御手法である.
OracleやMySQL, PostgreSQLといった多くのデータベースがトランザクション処理の実装にMVCCを採用している.
しかし,MVCCという言葉は「マルチバージョンで実装すること」以上の意味を持っていない.MVCCという概念が包含するコンポーネントは非常に多く,その種類と組み合わせも膨大である.
「MySQLとPostgreSQLはともにMVCCだからトランザクション性能は同じ」という言い方は明らかに乱暴であるように,MVCCの中での設計上の選択は数多く存在する.
この論文では,MVCCの設計と実装における重要な要素を四分類し,それぞれについてインメモリ・メニーコア環境でのベンチマークを行っている.
ACM Refs
Yingjun Wu, Joy Arulraj, Jiexi Lin, Ran Xian, and Andrew Pavlo. 2017.
An empirical evaluation of in-memory multi-version concurrency control.
Proc. VLDB Endow. 10, 7 (March 2017), 781-792.
DOI: https://doi.org/10.14778/3067421.3067427
なぜこの論文を紹介するのか
近年,トランザクション処理の研究領域において前提となる環境は,メニーコアを持つインメモリデータベースである.
このとき最大のボトルネックはディスクI/Oではなくキャッシュ競合や malloc/free といったメモリアクセスである.このため,単一バージョンのOCCが手法として選択されることが多い.
しかし,現実に市場で扱われているDBMSはといえば,PostgreSQLやMySQLといったオープンソースのDBMSから,SAP HANA, Oracleといったエンタープライズ系DBMSに至るまで,
ほぼ全てがマルチバージョン同時実行制御(MVCC)を用いている.
ここにアカデミアとインダストリアルのギャップがある.
さて,MVCCとは何か? という点について少し説明する.大枠はWikipediaの説明を読むと良い.
理論的な定式化が厳密になされている分野ではあるのだが,あえてざっくりした表現で説明すると,MVCCとは,その名の通り,「マルチバージョンのデータ構造を用いて同時実行制御を行う」ことである.
たとえば, 単純な配列の各要素に直接構造体を詰め込んでデータを管理するのが単一バージョンの同時実行制御だとする.ハッシュテーブルのようなものを想定すればよい.以下のような構造である.
# Monoversion
T1 : w(x)
T2 : w(y)
T3 : w(x)w(z)
[x3][y2][z3]...
対して,配列の各要素がポインタになっていて,そこから線形リストで各更新ごとのバージョンを辿れるデータ構造がMVCCである.
(もちろん,MVCCは理論的にはデータ構造の制約は存在しない.一例として線形リストを挙げた.)
# Multiversion
T1 : w(x)
T2 : w(y)
T3 : w(x)w(z)
[x*][y*][z*]...
| | |
[x1][y2][z3]
|
[x3]
MVCCでは,更新がin-placeに行えないため,書き込み時に必ずメモリ上に新しい領域を必要とする.また,不要に線形リストを更新するため,キャッシュミス回数も増える.
MVCCのほうが空間的にも時間的にも計算量が多いことは明らかである.
しかしMVCCはより広いトランザクションのスケジュール空間を許容する.仮に
T4: r(x)r(y)r(z)
というトランザクションが同時に走っているとしよう.
単一バージョンの同時実行制御であれば T1 と T3 はともに x を更新しているため,
T1とT3の実行の間に T4 が実行された場合は,他のトランザクションとの兼ね合いで直列化可能性(Serializability)に違反する可能性が出てくる.
これを安全に実行するためには,ロックを取るために待つか, T4 はアボートしなければならない.
どちらも性能に影響を与えることは言うまでもない.
さて, T4 のようなクエリはデータベース運用の現場では一般的なものである.SELECT COUNNT(*) FROM... といったクエリはしばしばこういった実行に展開される.
これが全てロックを取るかアボートする恐れがある,というのはかなり実用的ではない.
研究者にとっては無用なオーバヘッドが大きいとされるMVCCが,しかし依然として市場の大多数を支配していることにはこういった理由があるのではと考えることもできる.state-of-the-artのトランザクション性能は出なくとも,多様なクエリに対応できるスケジュール空間の広さがある.
さて一方で,MVCCのDBMSを実装する際には,MVCCの理論からは直交した実装上の選択がいくつか存在する.
こうした選択は各DBMSの実装内部に留まる話であり,研究の世界で議論されてはこなかったものである.
アカデミアとインダストリアルの壁を埋める同時実行手法がやはりMVCCしかないなら,MVCCの高すぎるオーバヘッドをどう削減していくか?というテーマこそが真に実用的な研究領域になる,ということもありえる.
以上の理由により,MVCCの特に実装面に注目して評価を行ったこの論文を紹介する.
1. Introduction
MVCCの手法は1970年代に確立されており,生成されるスケジュール空間についても既に証明されている.
が,本格的に実装され用いられ始めたのはこの10年のことである.
MVCCの強みは,一言で言うと理論的なスケジュール空間の広さ(CSRに対するMVSR[0])にある.
より実装に倒した言い方をすると,MVCCにはin-placeに更新をしないことによる恩恵がある.
特に, Read-Only Transactionの場合はどれだけクエリが重かろうが必ずAbortしない,という特性が非常に強い.
たとえば,シンプルなKVS上で単一バージョン(Monoversion)とMVCCの実装を比較すると以下のようになる.
## Monoversion
[x=2|10 < TS < INFINITY]
## Multiversion
[x=1|TS < 3] -> [x=2|TS < 5] -> [x=3|TS < 10] -> [x=2|TS < INFINITY]
x: key
TS: トランザクションのタイムスタンプ(論理的な実行順序)
in-placeにデータを書き換えるmonoversionの同時実行制御方式というのは,チェーン末尾のデータしか見えないものと同等だ.
つまり 10<TSのトランザクションしか read(x) 命令は成功しない.
一方でMVCCであれば,この場合いかなるタイムスタンプを割り当てられたトランザクションでも read(x) が成功する.
勿論,このチェーンをいつGC/コンパクションするか?という問題はある.
もし,”最新のデータ以外をGCする”というスレッドがバックグラウンドで走っているとすれば,
read が失敗することもありえるだろう.しかし,GCやロックを度外視すれば,理論的にはMVCCにおける read は必ず成功する.
この特性が,MVCCで”Read-Only Transactionはどれだけクエリが重かろうと必ずAbortしない” ことを保証している.
さて,ここ10年で一気に使われるようになったMVCCであるが、歴史はもっと古い.
- 1979: 初論文が出る
- 1981: InterBase(現在のFirebird)で実装される
- 1984: Oracle登場. いつからかは不明だがSIを使っている.
- 1985: PostgreSQL登場. MVCC. 初期はTime-traveling[1]という機能もあった.
- 2001: MySQL InnoDB登場. MVCCを使っている.
- そこからHekaton(SQL Server), SAP HANA, MemSQL, NuoDB, HYRISE, HyPerとMVCCの春が来た.
これほど普及している手法にもかかわらずMVCCには “Standard implementation” がない.
MVCCの実装手法にはいくつか設計上の選択があり,それぞれに非常に興味深いのだが,過去にそれを評価した文献を探すと80年代まで遡る. もちろんこれはディスクベースでシングルコアの環境でのベンチマークであり,現在のトランザクション研究の前提となるインメモリ・メニーコア環境での結果とは大きく異なる可能性がある.
ここがこの論文のContributionである.全ての実装上の設計と選択をインメモリ・メニーコア環境上で比較している.
しかし,ただ実装の効率性で殴るようなベンチマークになるとフェアではないので、
既存の各DBMSのアプローチを全てPeloton[2]に実装している.
2. Background
ここで既存のMVCCの実装を整理する.
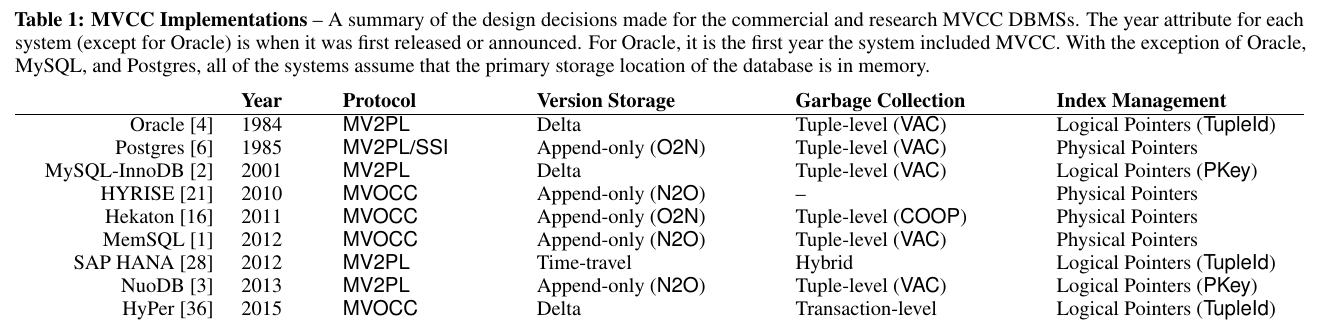
この図表は非常に面白い.
今後ドラスティックな変更が各DBMSに無い限り,数年間にわたって使い回せる表である.
ベンチマークにおける実装の話をすると,本論文におけるMVCCでは

という構造体を使いまわす.この構造体はインメモリDBにおけるMVCCの実装を最初に示した(と思われる)Hekaton[3]にならっている.
おおむね構造体の各メンバの命名通りの役割をしているため,説明は省く.
が,実装上の細かいポイントを述べると,ここでは txn-id の下位0bit目を排他ロックに用いる.
すなわちtxn-idをCompare-And-Swap(CAS)命令で書き換えることで,そのレコードの読み書き権限を得る.
なお,この実装はHekatonで提案されているそれとは異なる.Hekatonではbegin-tsやend-tsの下位0bit目をロックに用いており,構造体が少しコンパクトである.この論文では,複数の同時実行制御手法に対応する実装を行うために少し冗長な設計になっていると思われる.
3. ConcurrencyControl Protocols
この章では同時実行制御手法を複数検討している.
前提として
- Serializable
- tuple-level lock
- No range Query
- MVCCであることはphantom問題の解決とは直交しているため,ベンチを取る意味がない
を置いている.
3.1 MVTO
1979に発明されたTimestamp Ordering[4]のMVCC版.
Timestamp Orderingの基本は「トランザクションIDをSerialization Orderとして予め与えておき、それに違反する読み書きをしたらabort」というプロトコルである.
大まかには,各タプルに read timestamp write timestamp を付与し,これを更新することで直列実行との等価性を検証する.すなわち,write ts < my_ts のとき読めるし,read_ts < my_ts のとき書ける,といった様に(厳密には異なるが)規定される.読み書きはすべてタイムスタンプの更新を伴う.
これは前述した構造体に read tsを追加することで実装できる. begin-ts end-ts はそれぞれwrite timestampを記録する.
タイムスタンプの獲得はトランザクション開始時(beginning of read phase)とする.
この実装は既存のDBMSには存在せず理論のみが提案されているものである.
3.2 MVOCC
OCCを用いたMVCCの実装.
- read-phaseの最初にtidを決める.
- read phaseでは,自分が読める値(
begin-ts < ts < end-tsのタプル)を読む. - write-phaseでは
nextポインタに新しいレコードをCAS命令で繋げる. (事実上これでw-wの依存関係は潰せる.) txn-idにtidをセットしてロック済みとする.
OCCのvalidation phaseではread-setに入っているタプルが変化しているか(チェーンが伸びているか)を調べる.
この実装はHekatonのものと殆ど同じ.
3.3 MV2PL
この論文のAuthorに名を連ねるAndy Pavloが2016年のCMUの講義で「これは何でかわかるか?」と学生に聞いていた話が書いてある. 以下.
In a disk-based DBMS, locks are stored separately from tuples so that they are never swapped to disk.
This separation is unnecessary in an in-memory DBMS,
thus with MV2PL the locks are embedded in the tuple headers.
Andy Pavloは更にSIGMOD’17のKeynoteでもこの点がHekaton論文の偉大なcontributionであったと述べている.
要点は以下である.
- S2PLの実現のためにはリーダーライターロックが必要.
- このために
read-cntを構造体に追加.read-cntをincrementすることでリーダーロックを取る.- なお実際には
read-cntの64bitでライターロックも兼ねる.
- このために
- 2PLの性能を左右する大きな選択として,デッドロック回避アルゴリズムが挙げられる.
- Monoversionの場合は
no-waitが最もスケールすることが先行研究[5]で挙げられている
- Monoversionの場合は
3.4 Serilization Certifier
いわゆるSSI[6].
あるいはSSN[7]というより軽量な実装も論文が出ている.
これはどちらもr-wの依存関係がcyclicであるかどうかを検出する機構である.
3.5 Discussion
どの手法もconflictへの取り組み方が違う.
あるワークロードに強いものはあるワークロードに弱い.銀の弾丸はない.
- MV2PLはリーダーライターロックを使うため,
read命令でキャッシュを汚すオーバヘッドがある.- あるタプルへの読み書きが重なったら,どちらかがアボートする.
- MVTOは
read-tsを更新する.この点でMV2PLに近い挙動.- しかしロックで直列化しているわけではないので,読み書きが重なっても両方通りうることもある.
- MVOCCはリーダーロックも
read timestampも使わない.つまりr-wの検出をしない.- アボートに倒す実装になっており,偽陽性がある.
- long-running read-only transactionが不要にアボートしうる.いわゆるStarvation.
さらなる最適化手法も検討されている.
どちらも,「他のトランザクションにロックを取られているタプルを読み書きした場合にどうするか」という議論.
- speculatively read はHekatonのアプローチで,Dirtyな値を読んだ場合にそのタプルが永続化されるまで待つという手法.
- eagerly update は上記に加えて,投機的にそのタプルをさらに上書きするチェーンを伸ばしてしまう手法.これは
w-wの依存関係を作ってしまう.
これらのアプローチは,全てのトランザクションがコミットに至ると仮定した場合には,不要なアボートを削減できる.
ただでさえMVCCは新しいバージョンのタプルを生成するためmallocを発行したり,スレッドローカルな変数を多く用いることから,
実装上のオーバヘッドが高いと言われているため,このような投機的実行は一つの選択としてありうる.
しかし,上記二種の最適化は,いわゆる連鎖的アボートの回避スケジュールから回復可能スケジュールへの変更であるため,注意深く実装しなければオーバヘッドが上回ることもある.
と,色々と考慮すべき点はあれども,マルチコアにおける原則はdecentralized data structures/alghorithmsである.
4. Version Storage
MVCCは全ての更新を新しいバージョンの生成として行う.
ここで用いるデータ構造は問わないが,一般的にはポインタを使う線形リストで実装される.
MonoversionのDBMSに比べて,このリストの走査がパフォーマンスに与える影響というのが存在する.
もちろん空間計算量も多く取ることになるため,キャッシュを意識した実装が性能に影響するということもある.
ここの実装の差分がもたらす性能差についてこの章では見ている.
大別すると3つの手法がある.
4.1 Append-only Storage
PostgreSQL, Hekaton, MemSQLなどのアプローチ.
Lock-free Doubly Linked Listを(現実的な速度で?)扱うことは難しいため, 単方向リストになることが一般的.
方向性に細かい決定がある.まずは「チェーンの方向」.
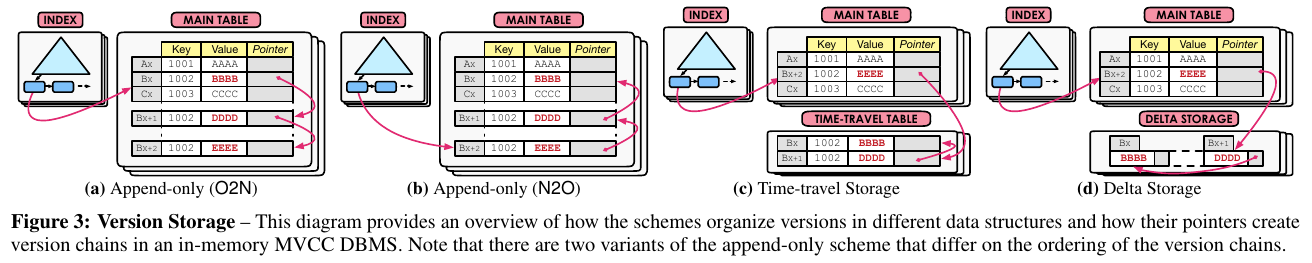
- oldest-to-newest(O2N): 古いデータから新しいデータに伸びていくリスト.
* indexを更新する必要がないが, pointer chasingが長引く可能性が高い. GCが細かく実行されれば問題ない. - newest-to-oldest(N2O): 新しいデータから古いデータに伸びていくリスト.どんな時でもindex(head)を更新することになる.
* セカンダリインデックスを実装している場合,こちらも含めてアトミックに更新しなければならない.
* 間接参照を用いることで解決できる.
さらに他にも方向性がある.「Blobが与えられた場合の挙動」が性能に影響する.
- Blobをコピーする: リストの各ノードで,構造体をまるごとコピーする.
- もちろん非効率だが,参照には優しい.
- 更新の差分だけを記録する(delta-update). MySQLの取っている戦略.
- リストを辿ることによって構造体を完成させる.このため更新に強いが参照に弱いと考えられる.
4.2 Time travel storage
こちらはSAP HANAが取っている戦略である.が,割愛する.
4.3 Delta Storage
MySQLとOracleが採用しているもの.
master versionとdelta storageを分離して管理する.
4.4 Discussion
かなり細かい実装上のポイントがある.
- append-only storageはanalytical queryに強い.全てのバージョンが連続してメモリに乗っているため,CPUのキャッシュに優しい.プリフェッチがきく.
mallocを工夫するのがポイント. メモリ上で連続したレイアウトに同じタプルが乗るようにするとよい.- indexの管理やdelta storageとのやりとりのロックを使うと,そこがボトルネックになる.ロックフリー化するとよい.
5.Gabage Collection
リストから不要な領域を削除したり,コンパクションを行うことをMVCCにおけるGCと呼ぶ.
GCにかかる時間が長いと単純にペナルティが大きい. が, 長大なリストを辿るのもオーバヘッドがやはり大きい.
このトレードオフをうまく吸収できる設計が,GCに求められている役割である.
GCの主な機能は,
- detect expired version
- 現在走っている全てのトランザクションIDより若いバージョンは削除(誰にも読まれない)
- これを実装しようとすると,全てのトランザクションで共有するデータ構造を必要とする.これはcentralized data structureになる.
- Silo[8]のようにepoch-based Commit/GCすると緩和できる.
- unlink those versions
- reclaim their storage
GCの設計は大きく2種類ある.
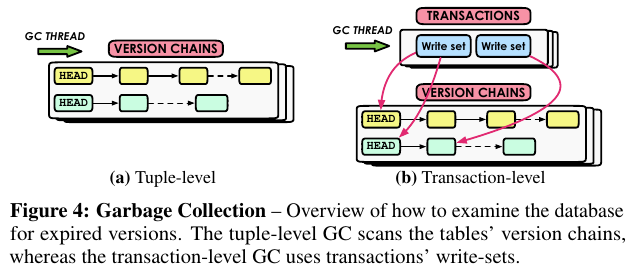
5.1 Tuple-level GC
一般的なMVCCのGCといえばこのスタイルだろう.
あるバージョンのレコードを意味するタプルが線形リストとして表現されるもの.
この場合のGC戦略はさらに細分化して二種類ある:
- VACUUM: PostgreSQLのものが有名.GC用のスレッドを作る. 一般的なやり方ではあるが,DBの規模とワーカスレッド数が巨大になると追いつかなくなってくる.
- COOP: 各トランザクションのワーカスレッドが,自分が触ったリストを最適化して帰っていく.
- これはO2N(oldest to newest)の時しかうまく動かない. 加えて殆ど触られないリストがある場合不要なレコードが残り続ける. これをHekatonでは“dusty corners”と呼んでいる.
5.2 Transaction-level GC
これは一般的なアプローチではない.トランザクションのRead/Write Setをそのままタプルの表現として用いるアプローチ.
つまりトランザクション構造体の線形リストとなる.
単純に考えると,タプルを malloc して memcpy するTuple-Level GCに対して,トランザクションのワーキングセットをそのまま move すれば良いため,
実装上の効率は良いと考えられる.
5.3 Discussion
Tuple-Level GC + VACUUMが最も一般的な選択である.この理由としては実装の容易さもあるだろう.
6. Index Management
セカンダリインデックスなどを考慮すると, Atomicityのためにはインデックスを更新するためのラッチの使い方が変わってくる.
ここにも大別して二つの戦略がある. それ以外はHybridと呼べる.
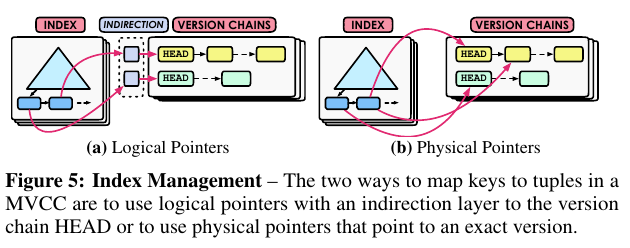
- Logical Pointer: 間接参照を用いて, アトミックにインデックスを更新する.
- 更新には強いが参照時に一回,無駄にメモリアクセスする可能性がある.
- Physical Pointer: インデックスに直接タプルを埋め込む.
- 参照は速いが,セカンダリインデックスをどう更新するかという問題がある(ナイーブには,ロックを使うしかない)
7. Experimental Analysis
本論文では上記の設計上の選択をすべてPelotonに実装してベンチマークを行っている.
このブログでは論文のベンチマーク結果を個々には取り上げず,概要のみ紹介するが,
それぞれの図は興味深い結果を見せているので,一読する価値はある.
Concurrency Control Protocol
同時実行制御手法については,先行研究で得られた知見とおおよそ同様の結果が得られた.
読取りロックを用いるS2PLや読取りタイムスタンプを用いるMVTOは read の多い参照系ワークロードでは性能が低下する.
しかし,読取りロックを用いないOCCは,局所性が高く競合する割合が増えるワークロードでは偽陽性のあるアボートをしてしまい,むしろ性能が落ち込む.
といった様に,先行研究で得られた知見と同等の結果が出ている.
Version Storage
それぞれの選択についての比較を行っている.
- Non-Inline Attributes: blobをコピーせず前のバージョンから持ってくる. full-copyしない戦略. 性能が2倍程度向上した.
- N2O/O2N: N2Oのほうが参照・更新の性能共に良い. IndexのHEADを差し替えるために間接参照を用いるなどのオーバヘッドを差し引いても良い.
- Append Only/Delta Update: 変更するテーブルの列数が多い場合,差分更新を行うDelta Updateは性能が上がる.が,10列程度では変化がない.
- Attributes modified: Delta Updateを採用した場合,クエリが変更する列数が増えるとむしろ性能が劣化する場合がある.
Gabage Collection
- VACUUM/Cooperative: それほどスレッド数の増減などを行った際の性能特性に差はない.
- が,総じてCOOPのほうが45%ほど性能が良い.
- Tuple-level/Transaction-level GC: Transaction-levelのほうがupdate-heavyなワークロードでは20%ほど性能が良い.
* 実装上のオーバヘッドを潰せたという以上の意味はないだろう.
Index Management
どのようなワークロードでもPhysical Pointerに対してLogical Pointerが25~40%ほど性能が良い.
8. Discussion
現状のベンチマークを踏まえて,
インメモリデータベース上でMVCCを実装する際の最も有効な選択はMVTO+N2O+Delta Update+Logical Pointer+Cooperative GCでの実装になるだろう,と述べている.
所感
Andy Pavloのチームは彼らが実装したPelotonをベースにここ数年,多くの論文を発表している.
RNNを用いたDBMSの自動管理などもその一つである.
研究者の手元に,コントロール可能なDBMSの実装があるというのは非常に重要で,DBMS研究が各コンポーネント(ログ・同時実行制御・オプティマイザ・etc..)のマイクロベンチマークに閉じず,
DBMS全体の性能に対する影響を計測することを可能にしてくれる.
このような論文はアカデミアとインダストリアルの架け橋になるものだと思う.
参考文献
[1] PostgreSQL: Time Travel, https://www.postgresql.org/docs/6.3/static/c0503.htm
[2] Peloton, https://github.com/cmu-db/peloton
[3] Per-Åke Larson, Spyros Blanas, Cristian Diaconu, Craig Freedman, Jignesh M. Patel, and Mike Zwilling. 2011. High-performance concurrency control mechanisms for main-memory databases. Proc. VLDB Endow. 5, 4 (December 2011), 298-309. DOI=http://dx.doi.org/10.14778/2095686.2095689
[4] Philip A. Bernstein and Nathan Goodman. 1980. Timestamp-based algorithms for concurrency control in distributed database systems. In Proceedings of the sixth international conference on Very Large Data Bases - Volume 6 (VLDB ‘80), Vol. 6. VLDB Endowment 285-300.
[5] Xiangyao Yu, George Bezerra, Andrew Pavlo, Srinivas Devadas, and Michael Stonebraker. 2014. Staring into the abyss: an evaluation of concurrency control with one thousand cores. Proc. VLDB Endow. 8, 3 (November 2014), 209-220. DOI=http://dx.doi.org/10.14778/2735508.2735511
[6] Alan Fekete, Dimitrios Liarokapis, Elizabeth O’Neil, Patrick O’Neil, and Dennis Shasha. 2005. Making snapshot isolation serializable. ACM Trans. Database Syst. 30, 2 (June 2005), 492-528. DOI=http://dx.doi.org/10.1145/1071610.1071615
[7] Tianzheng Wang, Ryan Johnson, Alan Fekete, and Ippokratis Pandis. 2015. The Serial Safety Net: Efficient Concurrency Control on Modern Hardware. In Proceedings of the 11th International Workshop on Data Management on New Hardware (DaMoN’15), Ippokratis Pandis and Martin Kersten (Eds.). ACM, New York, NY, USA, , Article 8 , 8 pages. DOI=http://dx.doi.org/10.1145/2771937.2771949
[8] Stephen Tu, Wenting Zheng, Eddie Kohler, Barbara Liskov, and Samuel Madden. 2013. Speedy transactions in multicore in-memory databases. In Proceedings of the Twenty-Fourth ACM Symposium on Operating Systems Principles (SOSP ‘13). ACM, New York, NY, USA, 18-32. DOI: https://doi.org/10.1145/2517349.2522713