論文紹介: Benchmarking Cloud Serving Systems with YCSB
書いた人: @nikezono
概要と紹介理由
少し間が空いてしまったが,今回もデータベース系論文から一本.
分散システムの時代が到来して,BigTableやRedis, MongoDBやCassandraといった”新しい”データベースが生まれてきた2010年.アカデミアにはある問題があった.それは,「これらの新しいデータベースを評価するベンチマークが無い」ということである.
旧来よりデータベースの性能をフェアに測定するために用いられていたベンチマークはトランザクション処理性能評議会(TPC)が定めたTPC-CやTPC-Hといったベンチマークであった.
これらのベンチマークは,データベースにデータモデリングの機能が備わっていることを暗に要求しており,マルチレコードのトランザクションや,JOIN 等の機能がないとクエリを書くのが難しいものだった.また,TPC-Cは物流,TPC-Hは意思決定(統計)といったように,特定のユースケースを想定していて,単純なKVSなどのNoSQLの性能を比較するには,明らかに不適切だった.たとえば,KVS上でTPC-Cの物流のクエリを実装しようとすると,Keyの設計だけで性能がひと桁変わりそうなものだ.
さて,そういうわけで,旧来のトランザクションを扱うデータベースとは異なる,新しいベンチマークが求められる時代である.また,新しいベンチマークでは,様々な尺度でのデータベースの性能特性の比較を行いたい.TPC-Cの性能が高くても,物流システムのバックエンドに据えた時の性能が良い,ということしか意味しないのでは困るからだ.もっと具体的に,たとえば,単純なINSERT の性能から,レンジスキャンが高速であるかどうか,とか,データの件数が増えたらどう,というレベルの話が知りたいわけだ.
Yahooはこうした問題意識から,この論文でYahoo Cloud Serving Benchmark(YCSB)を提案している.論文自体はプロジェクトの紹介と,アカデミアへの周知の意味が強いのか,「詳細はリポジトリ見ればわかるよな」という意思を感じる部分が多い.が,この論文以降,多くのデータベース系/トランザクション系論文が,評価実験のベンチマークにTPCとYCSBを両方採用しており,二つとも実装し実行することがスタンダードとなっている.これは, TPCが実世界ワークロードを模したベンチマークであるならば,YCSBは細かい性能特性を見るのに適している 設計となっているからだと思う.
YCSBを使いたいだけで,論文に興味はないという人
これでセットアップして,このあたりを参考にしてワークロードを作成してやるとよい.もし bin/ycsb した結果の Databases に自分がベンチマークしたいデータベースがない場合は,このへんを参考にドライバを書いてやるとよい.
Reference
Brian F. Cooper, Adam Silberstein, Erwin Tam, Raghu Ramakrishnan, and Russell Sears. 2010.
Benchmarking cloud serving systems with YCSB.
In Proceedings of the 1st ACM symposium on Cloud computing (SoCC '10).
ACM, New York, NY, USA, 143-154. DOI: https://doi.org/10.1145/1807128.1807152
Introduction
The large variety has made it difficult for developers to
choose the appropriate system. The most obvious differences
are between the various data models, such as the
column-group oriented BigTable model used in Cassandra
and HBase versus the simple hashtable model of Voldemort
or the document model of CouchDB. However, the data
models can be documented and compared qualitatively.
BigTableのような列指向モデルや,CouchDBのようなドキュメントデータベースは,定性的に評価はできても,定量的にそのパフォーマンスを評価することは難しい.なぜなら,アーキテクチャが全く違うからだ.
Understanding the performance implications of these decisions
for a given type of application is challenging. Developers
of various systems report performance numbers for
the “sweet spot” workloads for their system, which may not
match the workload of a target application.
アーキテクチャの違いはそのまま性能特性の違いであるから,定量評価というのも一筋縄ではない.
列指向DBは当然,列ごとの集計処理などが頻繁に行われることを想定しているし,クエリは同じでも,分散時のパーティションやシャーディングの構成次第で性能は大きく変わる.
データベース開発者はみな, sweet spot つまり最も性能が出るワークロードやセッティングでの評価や報告しかしない.それはセールス上当然ではあるが,やはり,多角的かつ定量的に評価できる枠組みが求められる.
We focus on serving systems, which are systems
that provide online read/write access to data.
このYCSB Benchmarkの面白いところは,たとえばWebアプリケーションのバックエンドにデータベースを使う際などを想定して, serving システムに振り切っているところだ.つまり,YCSBはWorkload Generatorであって,それぞれのデータベースの内部の実装は一切問題にしていないのである.TPCでは,ストアドプロシージャ等の形でデータベース内にTPCのクエリを記述し,それを実行することで性能を計測することが多いが,YCSBはJVM上で動くJavaアプリケーションが, read や insert update といったメソッドを実行するという形式をとっている.
たとえばRedisのドライバはこんな感じである.新しいデータベースを追加したいときは,単にreadやinsertのメソッドをoverrideして,そのデータベースをJDBCなりRedisラッパーなりを使って操作すればよい.こうすると,データベースの実装には手を入れずに,クラウド上のPaaSでもDBaaSでもなんでも同じ土俵で評価ができるというわけだ.
2. CLOUD SYSTEM OVERVIEW
この章では,Cloud-Serving Databaseが持つ特性について説明している.
2.1 Cloud Serving System Characteristics
- Scale-out: データ量の増大に対して,ノード台数を増やすことでカバーできること.性能を向上させることはここでは意味していない.
- Elasticaly: ダウンタイム無しでノードを追加したり,データを移行させられること.
- High availability: クラウドサービスでは物理故障もソフトウェアの故障も起こりうる.それでもサービスを止めない(あるいは,SLAを守る)可用性のこと.
このような性質を 全て 満たすのは,旧来のACIDトランザクションやリレーショナルモデリングによるデータ管理ではなかなか難しい.基本的に,マルチレコードのトランザクションはスケールアウトと相性が悪いし,故障時に可用性を上げるにはレプリケーションをすることになるが,これもトランザクションと相性が悪い.いかなるハードウェアを用いても,ネットワーク分断などは現実的に不可避のイベントだが,その際のデータ一貫性は,ACIDのモデルだとかなり厳格になり,一部のサービスを止めざるをえない.
そういうわけで,新しいデータモデリングや一貫性の考え方が登場してきて,今 cloud-serving なデータベース(いわゆるNoSQLムーブメント)として普及してきている.
2.2 Classification of Systems and Tradeoffs
この章では,NoSQL系のデータベースが持つトレードオフについて述べる.
Read performance versus write performance
readとwriteのシンプルなインタフェースだけを提供するKVSでも,アーキテクチャ次第で性能は大きく変わる.たとえば,全てのデータがメモリに乗るわけではない場合,read でメモリ上のバッファ(キャッシュ)にヒットしなかった場合,ディスクに対するランダムI/Oが発生することが考えられる.それは write でも同じことがいえる.
これを改善したいので,シーケンシャルI/Oにしたい,と考えると,たとえば更新の 差分(Delta) だけをディスクに書いていくことで, write をシーケンシャルにするというテクニックがある. これは read にも有効で,差分を集めていってオブジェクトを再構築すれば,readもやはりシーケンシャルI/Oになる.
ただ,もしも一部のカラムだけ(たとえば, recent_login_date )が集中して更新され,一部のカラム(たとえば, user_name)は殆ど更新されなかったという場合には,オブジェクトを再構築するコストは非常に高くなっていき, read 性能が落ち込んでいくことが想定される.これに対処するためのLSM-Treeといった技術も普及しているが,しかして,read と write のoptimizationにトレードオフがあることには変わりがない.
Latency versus durability
データベースの責務はデータを永続化することだが,「ディスクに書いてからユーザにレスポンスを返す」というのはレイテンシが大きくかかることが想像に難くない.
なので,メモリ上のデータ構造を更新しただけで,永続化はできていないがユーザにレスポンスを返して性能を向上させる,という思想がありうる.
たとえばRedisなどはデフォルトの設定では毎秒1回のfsyncを実行しており,これは逆に言うと「直近最大一秒以内の更新は電源を抜いたら消えるかもしれない」ということだ.一方で,このように永続性を犠牲にすることで,データベースのクリティカルセクションからディスクI/Oを飛ばすことができ,これは性能上非常に有用である.(たしか,初期のMongoDBも,メモリマップドファイルの更新のみしかやっておらず,永続化はカーネル任せだったんじゃなかったっけ?)
Synchronous versus asynchronous replication
これは上述したレイテンシと永続性の議論に似ているが,レプリケーションが可能なシステムにおいて,あるwrite命令はいつユーザにレスポンスを返せるか,という問題だ.マスターノードの更新が終わったら即ユーザにackを返す,というのでは,スレーブのレプリケーションがまだ完了していない状況なので,スレーブへの read リクエストが最新の値を読めない可能性がある(非同期レプリケーション).これはデータの一貫性を損なう可能性がある.たとえば,扱うデータが銀行の残高なら,おおいに問題だ.
一方で,これを厳格にやろうとすると,全てのスレーブに対するデータの書込みが終わってから,マスターがユーザにackを返すという仕組みになる(同期レプリケーション).これはレイテンシが大きく悪化することは想像に難くない.また,一部のノードが故障したり分断した場合には,write命令は失敗ということになる.これは可用性に影響を与える.
Data partitioning
同じインタフェースを提供するDBでも,バッチ集計やOLAP処理向けの列指向DBや,OLTP向けの行指向DBがある.それぞれ,データの持ち方が異なるため, read writeについても, クエリのアクセスパターンについても異なる性能特性を示す.
2.3 A Brief Survey of Cloud Data Systems
この論文でYCSB Benchmarkを用いて評価されているのは以下のDBたち.
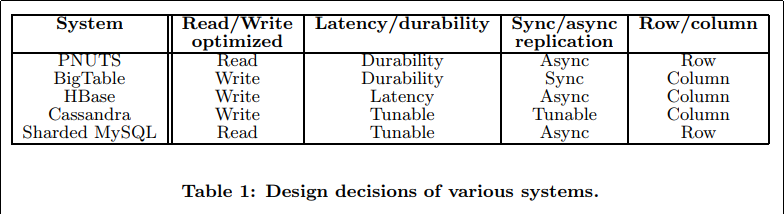
また,これらのDBが前述したトレードオフのどれを選択しているのか記している.
4. BENCHMARK WORKLOADS
YCSB Benchmarkでは,Workloadを自由に作成し,様々な尺度で性能を比較することができる.Workloadには変数とスケールファクターがある.
変数は,ワークロードの特性を決めるものだ.たとえば,CGM系のWebアプリのバックエンドなら,参照が多くアクセス頻度は冪乗則になる,等を決定する.
スケールファクターは,文字通り,データの件数が増えた際の挙動を計算するためのものだ. elasticでscalableなデータベースなら,件数が増えると分散システムのノード数も増えると想定できる.そのときの性能特性の変化を確認できる.
ただし,実は論文中で紹介されている変数やスケールファクター以外にも,多くのパラメータが追加されている.GitHubのリポジトリが最新のデータなので,それを見るのが一番手っ取り早い.
以下がYCSB Benchmarkでoverrideする必要があるインタフェースである.
• Insert: Insert a new record.
• Update: Update a record by replacing the value of one field.
• Read: Read a record, either one randomly chosen field or all fields.
• Scan: Scan records in order, starting at a randomly chosen record key. The number of records to scan is randomly chosen.
また,データの分布も選択できる.
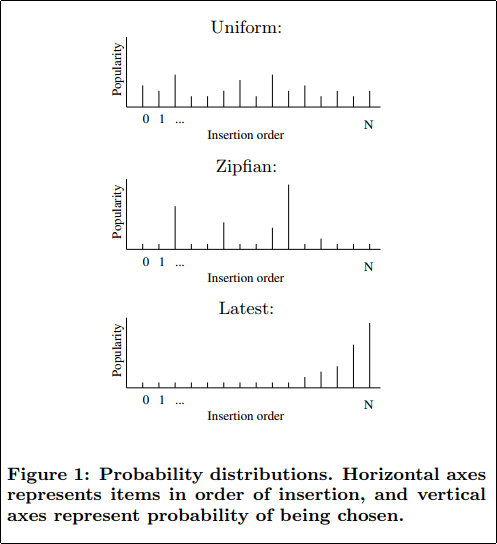
とは言え,殆どのワークロードでは Zipfian が選択されている.Twitterのタイムライン等のユースケースでもおそらくそうなるだろう.Latest は,ユーザ毎のフィルタをかけない全てのデータのタイムラインになる.
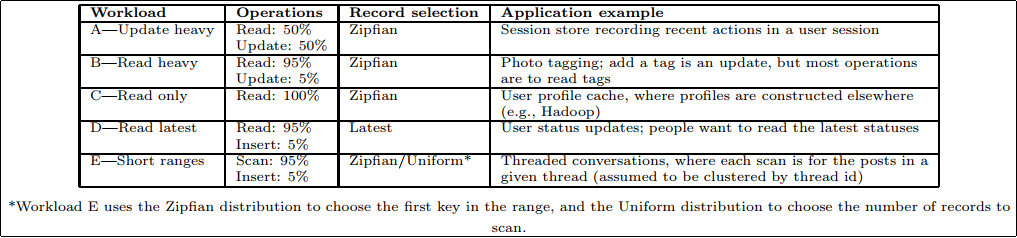
プリセットのワークロードの一覧は上記.このように,YCSB Benchmarkは4つの命令をどのような割合・分布で実行するかということしか規定しない. だが,これの組み合わせのみで,自社や自分のアプリケーションと同じ想定のワークロードを生成し,データベースを比較評価することが可能だと考えているのだろう.
ちなみに,最新のYCSBでは Read-Modify-Writeというインタフェースが追加されており,それを使ったWorkload Fがプリセットに追加されている.
6. RESULTS
さて,YCSB Benchmarkは極めて簡単な仕組みなので,GitHubからcloneして,自分で動かしてみるのが一番よい.が,この論文中で実験した結果について簡単に紹介する.この論文中の記述は2010年のものであるため,参考記録程度に考えると良い.
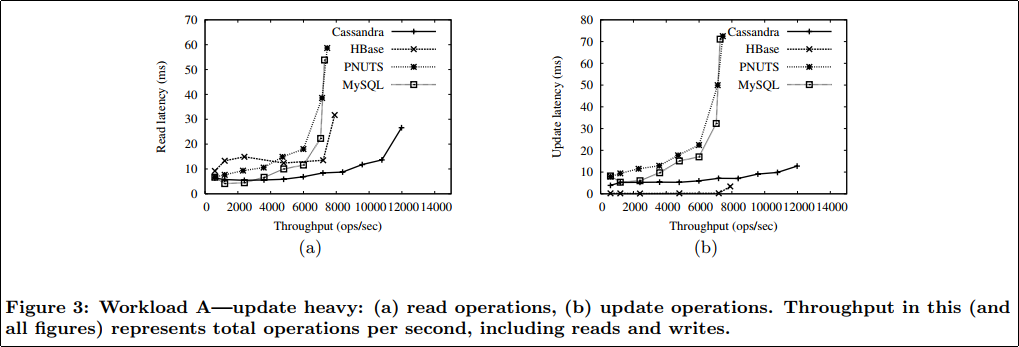
Cassandra, which is optimized for write-heavy workloads, achieved the best throughput and the lowest latency for reads. At high throughputs, Cassandra’s efficient sequential use of disk for updates reduces contention for the disk head, meaning that read latency is lower than for the other systems. PNUTS has slightly higher latency than MySQL, because it has extra logic on top of MySQL for distributed consistency. HBase had very low latency for updates, since updates are buffered in memory.
Update-HeavyなWorkload Aでは,Cassandraが非常にうまくやっていることが見て取れる.
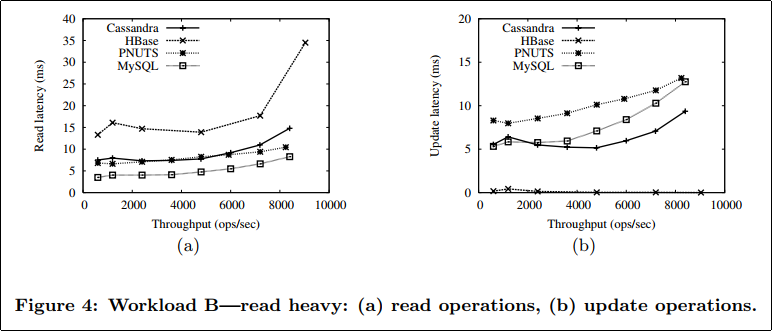
As the figure shows, PNUTS and sharded MySQL are now able to provide lower latencies on reads than either Cassandra or HBase. Cassandra and HBase still perform better for writes. The extra disk I/Os being done by Cassandra to assemble records for reading dominates its performance on reads. Note that Cassandra only begins to show higher read latency at high throughputs, indicating that the effects matter primarily when the disk is close to saturation.
対して,Read-HeavyなWorkload Bでは,MySQLやPNUTSのread optimizationがよく効いている.が,一方で,わずかなwrite queryのlatencyという点では,MySQLもPNUTSもCassandraに負けている.
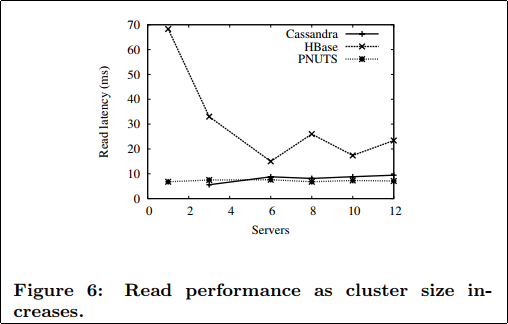
We first tested the scaleup capability of Cassandra, HBase and PNUTS by varying the number of storage servers from 2 to 12 (while varying the data size and request rate proportionally). The resulting read latency for workload B is shown in Figure 6. As the results show, latency is nearly constant for Cassandra and PNUTS, indicating good elastic scaling properties. In contrast, HBase’s performance varies a lot as the number of servers increases; in particular, performance is better for larger numbers of servers. A known issue in HBase is that its behavior is erratic for very small clusters (less than three servers.)
同じWorkload Bでも,スケールファクターを変更するなどして,ノード台数を変えて性能を測ることもできる.(これまでの図表はノード台数は6で固定だった)
綺麗にscale-outするCassandraとPNUTSに対して,HBaseは性能が安定しない.サーバ台数が少ない際の挙動が不安定であることは known-issue であるようだ.
所感
TPCという古い遺産を引きずっていたアカデミアに,より汎用的で extensible なベンチマーク環境が登場したという点で,この論文の意義は大きい.後続する多くの研究論文ではこのYCSB Benchmarkが用いられている.
一方で,このYCSB Benchmarkには重要な問題があると個人的には思っている.それは, あくまでWorkload Generatorとしての責務しか持たず,Javaで書かれている ことだ.
何が問題なのかというと,たとえばCで書かれた高速なトランザクション処理を得意とするデータベース(最近のアカデミアの流行りだ)をテストする際に,あまりにも JNIのオーバーヘッドが大きすぎる ということにある.
これを嫌ってか,YCSBのドライバをJavaで書き,JNIを通してデータベースをコールするという,この論文が期待するアプローチではなく,CでYCSB相当のワークロードを自分で書いて,その結果を論文に載せるというアプローチが普及している.(有名ドコロだと,SoSP ‘13のSiloとか,SIGMOD ‘15のFOEDUSとか,SIGMOD ‘16のERMIAとか)
これではYCSB Benchmarkの extensible な良さ,つまり,提供されたインタフェースをoverrideしたJavaのコードを1ファイル書いてやるだけで横断的にあらゆるDBの比較ができる,という点が失われてしまう.
アカデミアのデファクトスタンダードになりながらも,実際にそのコードは使われていないというのは,非常に歯がゆいものがある.