論文紹介: Critical sections: re-emerging scalability concerns for database storage engines
書いた人: @nikezono
概要と紹介理由
あらゆるプログラムには並列化しても性能がこれ以上上げられないという限界がある.
アムダールの法則やUniversal Scalability Lawなどで説明されてきたように,プログラム中に存在する「並列化できない部分(Critical Sections)」がボトルネックになるのである.
分散システムやGPU,メニーコアといった様に,可能な限り並列計算を行うことでプログラムの性能を向上させる,というトレンドがある今,アムダールの法則やUSLはより重要さを増している.この法則に立ち向かうには二つのアプローチがある.
- アルゴリズムを変える: 可能な限り並列化できる計算処理にプログラムを変更する
- Critical Sectionsの実装を変える: ロックを粗粒度から細粒度にするなど,実装を変えることで並列度を上げる.
前者の変更は,アプリケーションのロジックに踏み込むものになりうるし,深い議論を要求する.対して後者は,アプリに対して透過的に行える変更であり,アルゴリズムの変更とは直交している.
この論文では,後者に対する評価を行っている.いくつかの同期プリミティブを実装・評価し,開発者にとって最適なクリティカルセクションの実装方式を示唆している.ここでは,データベースに対して同期プリミティブを差し替えていく評価手法をとっている.
Reference
Ryan Johnson, Ippokratis Pandis, and Anastasia Ailamaki. 2008.
Critical sections: re-emerging scalability concerns for database storage engines.
In Proceedings of the 4th international workshop on Data management on new hardware (DaMoN '08),
Qiong Luo and Kenneth A. Ross (Eds.). ACM, New York, NY, USA, 35-40.
DOI=http://dx.doi.org/10.1145/1457150.1457157
Introduction
データベースの性能は,理想論を言えば,無限にクライアントが増えても,無限にスループットが上がり続けることが望ましい.
が,あらゆるソフトウェアと同様に,そうはいかないのが自然の摂理である.
過去,データベースの性能は,ディスクの帯域であったり,I/Oの性能であったり,計算リソース(CPU/GPU/etc)の性能であったり,といった要素によって律速されていた.それらは全てデータベースから見れば外部要因である.
高速なディスク,I/O,そして潤沢な計算リソースが揃った時,データベースというソフトウェアの中でボトルネックになるのは,内部のデータ構造に対するロックや,データ競合を防ぐための同期といったクリティカルセクション である.ましてや,100コア,1000コアといったプロセッサが開発されようというこのご時世である.一つの巨大なロックのせいで,CPUコアを一つしか動かせないというのでは,ハードウェアの性能を使いきってスループットを向上させることはできない.
過去のDBMS研究はこの観点を軽視しており,結果として現行のDBMSは軒並み低いスケーラビリティを示している.
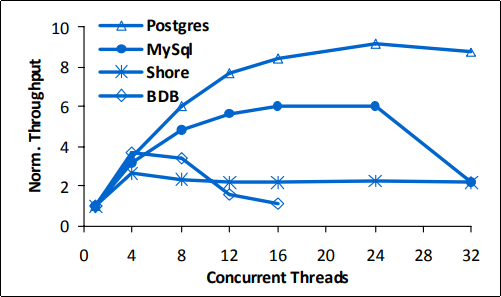
Ryan Johnson, Ippokratis Pandis, Nikos Hardavellas, Anastasia Ailamaki, and Babak Falsafi. 2009. Shore-MT: a scalable storage manager for the multicore era. In Proceedings of the 12th International Conference on Extending Database Technology: Advances in Database Technology (EDBT ‘09), Martin Kersten, Boris Novikov, Jens Teubner, Vladimir Polutin, and Stefan Manegold (Eds.). ACM, New York, NY, USA, 24-35. DOI=10.1145/1516360.1516365 http://doi.acm.org/10.1145/1516360.1516365
※ 注: この論文は2008年のものであり,最新のMySQLやPostgreSQLがこのような結果を示すとは限らない.
Critical Sections Inside DBMS
同研究グループのShore-MT論文では,PostgreSQLやMySQLといったデータベースも,同時に扱えるワーカスレッドの数に限界を抱えており,わりと早期に性能が落ち込むことが示されている.これはデータベース内部で扱っているロック等のクリティカルセクションが原因であると考えられる.
では,実際にDBMS内部に存在するクリティカルセクションを見てみよう.
基本的に, クリティカルセクション とは,複数のスレッド/ノード等が必ず 同期しなければいけない処理ステップ のことであり,論理的に も物理的にもスケールしえないコードパスのことを指す.
たとえば,
SELECT COUNT(*) FROM user WHERE user.something_flag = true;
といったクエリがあるとき,データベースをシャーディングなりパーティショニングなりしていれば,タスクを複数台のマシンで分割して並列に実行することができる.この結果,
Node 1(user_id[1...1000]): 245
Node 2(user_id[1001...2000]): 523
Node 3(user_id[2001...3000]): 11
といったそれぞれのSELECT COUNTクエリの結果を足せば答えが出ることになる.
この「足し算」がクリティカルセクションである. この処理は何台のノードがあろうと分割して行うことはできず,全ノードが同期する必要がある.
クリティカルセクションの変更や修正とは,この同期を効率化することを指す.たとえば,上記のような問題では,全ノードが計算終了を待つよりは,木構造で結果を同期していく等の修正をしたほうが,下位のノードは早く同期待ちから抜けられる様になるだろう.
このクリティカルセクションは,DBMS内部には以下がある:
バッファプール管理(Buffer Pool Manager):
PostgreSQLやMySQL等のデータベースは,ディスク上で永続化されているデータをメモリ上でバッファリングしている.これはページという単位で行われることが一般的である.このページ管理にはハッシュテーブルのようなデータ構造や索引が使われる.このハッシュテーブルには,複数のスレッドやプロセスから同時にアクセスされ,更新と参照が同時並行に行われうる.既に削除されたページのポインタを掴んでしまったり,ハッシュテーブルの拡張(extend)やメモリからページを捨てる(evict)に他のスレッドが巻き込まれないように,(トランザクションとは無関係な) ロックを用いてデータ構造を守る必要がある.
バッファプール管理においては,ひとつのページを読取り完了するためだけにだいたい3-4のクリティカルセクションが実装される.
ロック管理(Lock Manager):
トランザクションを用いるデータベースでは,ロックを獲得することによってデータの一貫性を守る.
ロックは粒度による分類がある.粗粒度で,データベース全体をロックすれば,すべてのクエリは完全に直列に実行する以外許されなくなるが,並列性が完全に失われる.細粒度で,行やレコードレベルでロックをすれば,並列性を向上させることができる.
しかし,行ごとにロックオブジェクトを用意すると,データベースの行数に比例してロックオブジェクトも増大していくという問題がある.そこで,ここでもハッシュテーブル等を用いて,固定数のロックオブジェクトをハッシュ関数によって振り分けて共有する,というアプローチ が取られることがある.このアプローチを取る場合には,やはりバッファプール管理のときと同様に,ハッシュテーブルの操作に関するクリティカルセクションが存在するため,データ構造を守るためのロックを使う必要がある.
優先度つきのロックなどを実装する場合には,ハッシュテーブルの各バケットに連結リスト(LinkedList)をぶら下げて,リストの順番でFIFOにロックを獲得できるように…といったアプローチもあるだろう.この場合,連結リストの操作にもやはりロックを用いてデータ構造を守る必要があることは言うまでもない.
ログ管理(Log Manager):
ソフトウェアとしての動作ログとは別に,データベースは永続性のためにログを書き出す.これは トランザクションログ というものだ.このログが壊れてしまっては,データベースは場合によってはリカバリが不可能になるため,必ず壊れないようにログを書き出す必要がある.
(フォーマットによるが)一つのログファイルにログを書き出す場合,メモリ上にログをバッファリングするためのデータ構造(リングバッファや連結リスト)を用意し,そこに各トランザクションがログ情報を送付していく,というアプローチになることが多い.この場合,当然このリングバッファや連結リストをデータ競合から守るために,やはりロック等を用いて保護する必要がある.
ディスク管理(Free Space Management):
ファイルシステムを経由せず,ディスクの空き領域のセクタを直接管理するような実装をしているデータベースの場合,空き領域情報を管理するデータ構造が必要となる.当然,これも並行アクセスによって不正な領域を指し示す事のないように,ロックなどを用いて保護する必要がある.
トランザクション管理(Transaction Management):
データベース/トランザクション系の論文で使われる ロック という言葉はほぼすべてこれを指す.マルチスレッドで並列実行を行っても,アクセスを直列実行した際と等価な順序にオーダリングするために,ロックを用いる.
ここまでに出てきた「ロック」という言葉は,このトランザクションに関するもの以外は,データ構造の保護など,データベースがソフトウェアとして壊れないための機構 であり,意味論的にロック(Lock)と区別して ラッチ(Latch) と表現されることが多い.
クリティカルセクションの実装と改善
ここまで見てきたように,同じデータ構造に対する並列実行を許容するデータベースというソフトウェアには,至る所にクリティカルセクションがある.これはアムダールの法則を考えるとあまり良い選択とは言えない.
アルゴリズム中で使われる ロック とデータ構造保護のために使われる ラッチ はともにクリティカルセクションであり,両方が改善の余地を持つ.論文中では,Shore-MTに対してアルゴリズムの変更とラッチの修正を行い,その結果をベンチマークした.
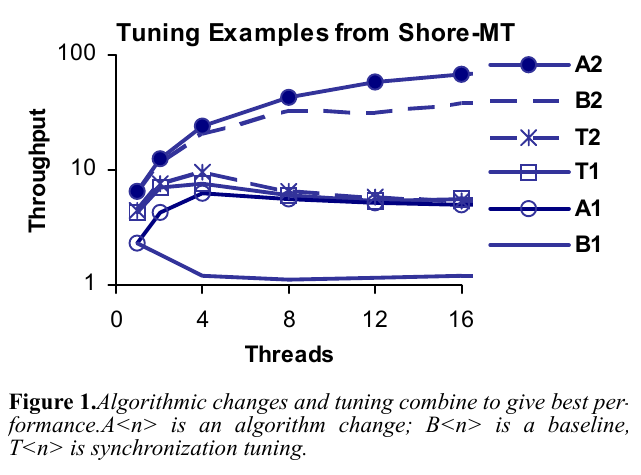
ロックの修正とラッチの修正はどちらも有効であることがわかる.両方を行うことが望ましい.
クリティカルセクションの基礎
クリティカルセクションとはどういうもので,どのような影響を及ぼすかは分かった.
ここでは,クリティカルセクションをどう実装するのか,そのプリミティブについて分類している.
- ミューテックス(Blocking Mutex): 多くのOSで実装されている.カーネル(スケジューラ)に対してブロッキングすることを通知し,強制的にコンテクストスイッチを行い,次のタイムスライス以降割り当てがされない状態にする.ミューテックスで保護されたブロックに侵入できるスレッドは一つであり,ミューテックス待ちのスレッドは一人ずつカーネルに起こされていく.
- 利点: 無駄にCPUサイクルを消費せず済む.
- 欠点: 寝て起きる,という構造上コンテクストスイッチが二回起こる.ロック/ラッチにかかる時間が極めて短い場合は,オーバーヘッドが大きい.
Mutex mutex;
mutex.lock()
do_something()
mutex.unlock()
- テスト・アンド・セット スピンロック(Test-And-Set Spinlock): TASと呼ばれる.ひとつのフラグをロック/ラッチと見立てて,スピンを行うシンプルな実装.テスト・アンド・セット命令ないしそれに相当するCPU命令が実装されている必要がある.テスト・アンド・セットにテスト・アンド・テスト・アンド・セット(TATAS)や指数関数バックオフロック等の亜種がある.
- 利点: 待ち時間は最も短く済む.
- 欠点: スピンはユーザランドで行われるため,カーネルからはそのスレッドが 無駄なスピンをしている かどうかわからない.無駄にサイクルを消費する可能性がある.また,全コア/スレッドで一つのフラグを共有するため,キャッシュ競合が頻発する.
flag = false
while(true){
if(TestAndSet(flag, false, true) { // address, expected, desired
// here is mutual exclusive block
do_something()
}
}
- キューベースのスピンロック(CLH Lock/MCS Lock/etc): 連結リストの各ノードにフラグを用意し,それをロック/ラッチと見立てる実装.ロックを解放する
unlock処理の際に,自分のフラグではなく後続ノードのフラグを変えてやることでロックを受け渡す.- 利点: 自分だけのローカルなフラグでスピンするため,キャッシュに優しい.また,FIFOにロックを獲得出来るため,公平である.
- 欠点: 連結リストのノードをメモリ上でアロケーション/管理するコストが,スピンロックより高い.ノードの再利用をしようとすると,よりコードは複雑になる.
class Node {
bool flag;
Node* next;
Node(): flag(false), next(nullptr){} // constructor
}
node = new Node;
GlobalList.push(node);
while(!node->flag){} // spin
do_something();
node->next->flag = true; // it means unlock and notify next node
- リーダーライターロック: データ競合は読取り同士の競合では発生しないことから,「ロック」という概念を「読取りロック(共有ロック)」と「書込みロック(排他ロック)」に分離し,共有ロックは複数のスレッドが取れる,というアプローチを取るロックの実装.
- 利点: 参照が多いワークロードでは,ロックの効能と並列性を同時に享受できる.
- 欠点: リーダーが多すぎると,排他ロックを獲得したいスレッドが一向にロックを取れないことがある.
lock = 0x0 // using lower 1 bit for writelock, upper bits for readlock
void write_lock(){
while(true){
test_and_set(lock, 0x0, 0x1)
}
}
void read_lock(){
while(true){
lk = lock.load()
if(lk & 1) continue;
test_and_set(lock, lk, lk+2) // increment upper bits
}
}
- 楽観的ロック(Optimistic Concurrency Control): 前にも紹介した様に,「自分の実行中に他のスレッドがデータを変更しない」と仮定して,「ロックを取ったことにして」実行を進めるアプローチ.バージョン比較などでロックを代用する.
- 利点: 参照が多いワークロードでは,リーダーライターロックよりもさらに並列性が高まる.キャッシュを一切汚さず進行出来るため.
- 欠点: 参照時にバージョン(場合によっては,それとデータそのものも)のコピーを取る必要がある.この空間オーバヘッドが大きい.
class Object {
uint64_t version;
void* data;
}
object = new Object;
// start processing
uint64_t version = object->version;
void* data = object->data;
do_some_processing()
// end processing
uint64_t end_version = object->version;
if (version != end_version) exit(1);
※ 本当はsnapshot read と呼ばれるテクニックが必要となるが割愛した.
※ なお,OSによっては,ブロッキングとスピンロックを組み合わせた アダプティブミューテックス が実装されている.コンテクストスイッチにかかる時間くらいは投機的にスピンで待ってみて,それ以上かかってしまったらコンテクストスイッチする,というもの.また,キューロックとリーダーライターロックを組み合わせることで,リーダーライターロックの欠点を解消するアプローチもある.勿論,アダプティブミューテックスロックとキューロックとリーダーライターロックを全て実装することも出来る.これは 分類ではなく特性の紹介 である.
- ロックフリーデータ構造(Lock-Free Data Structure): 進行保証を持つロックフリーなデータ構造を使ってプログラムを構成する.
- 利点: プリエンプション耐性が高い.ロックを用いるプリミティブは, ロックを獲得しているスレッドがコンテクストスイッチしてしまうと 一気に全体の進行が止まるという欠点があり,マルチスレッド環境でOSのスケジューラの影響を受けやすい.この問題をロックフリーデータ構造は解決している.
- 欠点: ライブロックに悩まされる.Wait-Freeデータ構造を実装することでこれも解決できるが,これは一般に実装上のオーバーヘッドが高い.
- トランザクショナルメモリ(Transactional Memory): データベースにおけるトランザクションと同じように,「命令列をアトミックに実行してくれる」ことを保証するメモリを使う.ハードウェアトランザクションメモリと,ソフトウェアトランザクションメモリが存在する.どちらにしても,命令列がアトミックに実行されるということは,ロックを使った際と同じ効能が得られることを意味する.
ベンチマーク
上記の様々なクリティカルセクションの実現手法を実装し,ベンチマークしている.
それぞれのベンチマークでは,N個のスレッドを立ち上げ,1秒間全力でそれぞれのスレッドがクリティカルセクションを通過していった際のスループットを計測している.
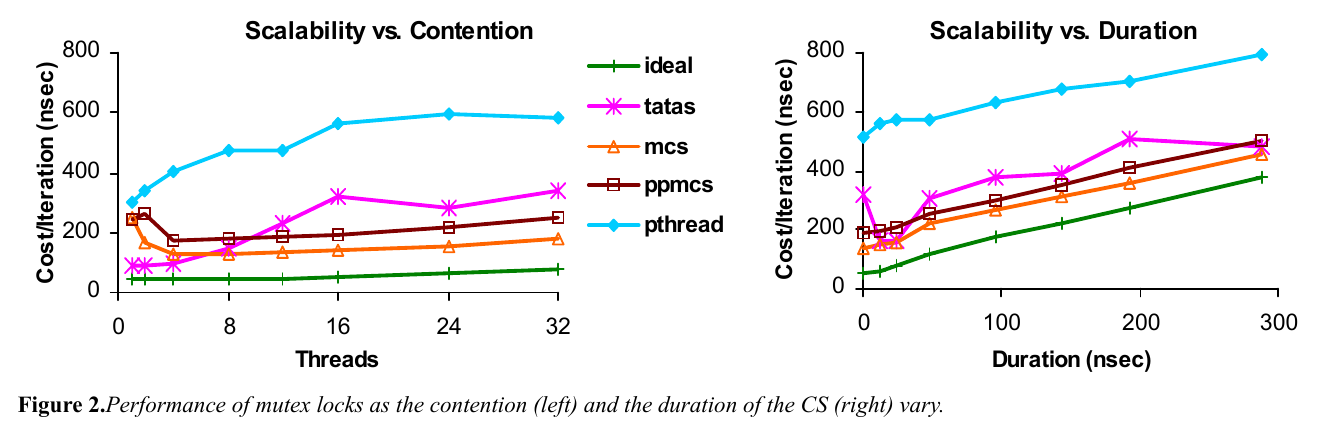
図左は4つのロック実装の性能を評価している.縦軸は一回のクリティカルセクション実行あたりの時間(ナノ秒)で,横軸はスレッド数.一つのスレッドしかクリティカルセクションには侵入出来ないため,スレッド数を増やせば増やすほどアクセスの競合が起こる.
理想論(ideal)としては,スレッド数が増えても一回あたりのクリティカルセクション実行の時間は変わらないで欲しいところだが,そうはいっていない.たとえばLinuxのネイティブ実装である pthread_mutex はかなり性能が低いことが見て取れる.テスト・アンド・セットのスピンロックは高速だが,同じアドレスで全スレッドがスピンすることから,キャッシュ競合の影響が強く,MCSロックなどのキューロックにはマルチスレッド性能が及んでいない.
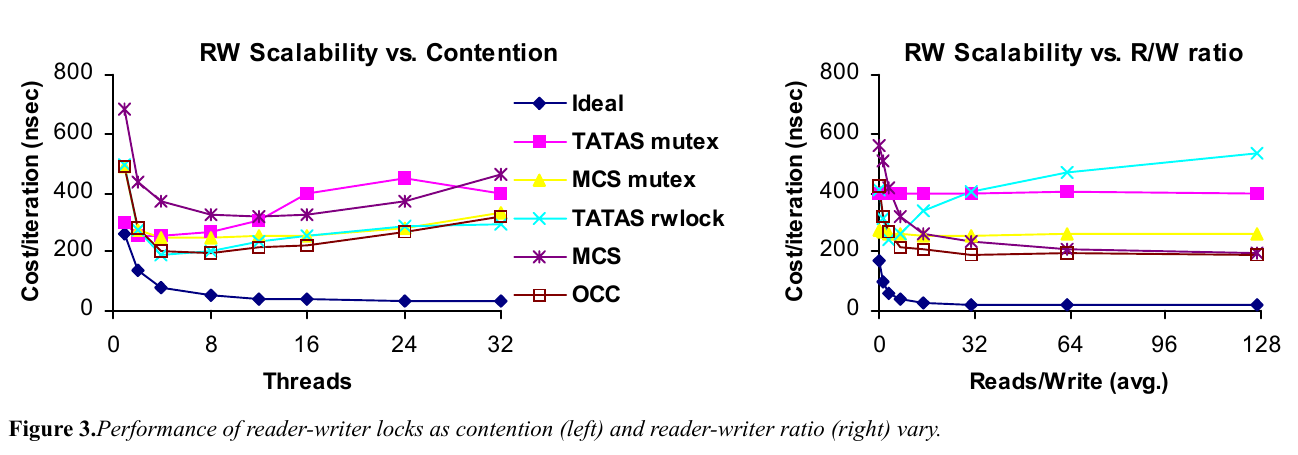
こちらはリーダー数とライター数を変化させ,比率を変えた際のベンチマークである.
図左は,7:1でリーダーが多い場合のベンチマークである.リーダーライターロックを TATAS rwlock と MCS に導入している.リーダーライターロックは,実装上のオーバーヘッドが高く,スレッド数が少ないうちはシンプルなミューテックスのほうが有効に機能する.
図右は,スレッド数を16に固定し,リード/ライトの比率を変えた際の性能比較である.さきほどの参照過多のワークロードと異なり,書込み比率が高くなると MCS がうまく機能していることがわかる.
結論
ソフトウェアを並列実行するためには多くのクリティカルセクションが必要となる.
アルゴリズムの変更も正しいアプローチだが,クリティカルセクションを実装するための同期プリミティブを変更することもまた,有用なアプローチである.
この論文では,同期プリミティブをそれぞれマイクロベンチマークし,比較・評価することによって,それぞれのワークロードの特性における同期のの性能を調べた.
結論としては,
- スレッド数が少ないうちは,1bitで実装できるテスト・アンド・セットのスピンロックが高速である
- MCSロックはスレッド数が増えてもキャッシュ競合の影響を受けず,スケールする
- リーダーライターロックはコストが高く,リーダーが少ない場合はシンプルなミューテックスに劣る
- 楽観的ロックはライターが多い状況でも強い
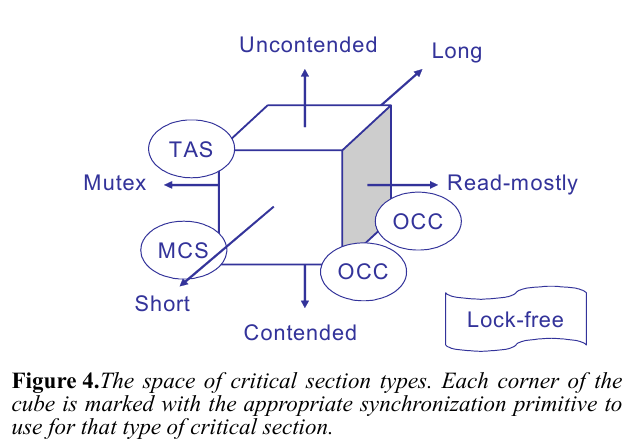
などなど.これらからわかった特性を論文中では八象限の図にまとめている.
所感
この論文は少し古いショートペーパーであるが,同期プリミティブを多く紹介しているという点で面白い.
ここで言われている同期プリミティブはそれほど色あせたものではない.2017年の先端研究でも,MCSロックやOCCの亜種などは未だに登場している.
同期プリミティブの実装それ自体が,クリティカルセクションの性能を変えるため,アルゴリズムも勿論のことながら,これに取り組むことに意義がある,というのは,なかなか興味深い知見だ.