論文紹介: Understanding User Goals in Web Search
書いた人: @nikezono
概要と紹介理由
ヤフーがディレクトリ検索サービスを終了したニュースは記憶に新しい.「このようなWebサイトが世の中にはあります」という分類から提示していくような検索サービスはもはや使われず,
Googleのようなキーワード型の検索エンジンが日常の一部となった.
何かを知りたい時,何かをしてほしいとき,何かを探しているとき.
その述語がなんであれ,わからない「何か」 があればとにかくGoogleの検索ボックスに入力してみる,というのは今ではごく自然なことだ.
ここで情報検索システムには課題がある.それは,ユーザがそのクエリに期待するゴールは何か? ということである.
たとえば私が “nike” とGoogleに入力する時,以下のゴールを期待する場合がある.
- ナイキのスニーカーが欲しいので,公式サイトのショッピングカタログが見たい
- ナイキの株価推移を見て,デイトレーディングの参考にしたい
- サモトラケのニケという言葉を聞いたが,何なのかわからないので,調べたい
- 自分のハンドルネームのミスタイプ.あるいは,”nikezono” と補完して検索してくれることを期待している.
このように,キーワード型の検索エンジンにおいて,ユーザが入力するクエリには,いくつかの側面がある.
この側面を無視して,従来のPageRankに代表されるアルゴリズムで,算出された文書の重要度でランキングをしても,ユーザにとって期待通りの結果が得られるとは限らない.
ユーザが求めているのは,その単語にマッチする重要文書とは限らないからだ.
この論文は,まさにそうした問題意識について焦点を当てており,当時からヤフーの研究開発者たちがこの観点でWebの検索に向き合っていたことがわかる.
少し古い論文ではあるが,ここで語られている議論はExploratory SearchやCHIIRといった名前で今現在も研究されている内容と方向性を同じくする議論である.
Reference
Daniel E. Rose and Danny Levinson. 2004.
Understanding user goals in web search.
In Proceedings of the 13th international conference on World Wide Web (WWW '04). ACM, New York, NY, USA, 13-19.
DOI=http://dx.doi.org/10.1145/988672.988675
Abstract
これまで,Webの検索にまつわる研究は,「どうやって検索するか?(インタフェース)」と「何を検索しているか?(クエリと文書集合とのマッチング)」の二つの側面を検討することが一般的であった. 「なぜ検索をしているのか?」 という観点について研究がなされることはなかった.
本研究では,この観点について研究する.クエリの分類を行ったところ,二つの分類ができた.
- “resource-seeking” 型の検索: 従来より研究の対象とされていた,ユーザが特定の文書のヒットを期待して行う検索.
- “navigational” 型の検索:
この二つの検索行動の分類についてより詳細に議論する.
## Introduction
The “why” of user search behavior is actually essential to
satisfying the user’s information need. After all, users don’t sit
down at their computer and say to themselves, “I think I’ll do
some searches.” Searching is merely a means to an end – a way to
satisfy an underlying goal that the user is trying to achieve. (By
“underlying goal,” we mean how the user might answer the
question “why are you performing that search?”)
ユーザの情報欲求を満たす上では,「なぜ」ユーザが検索をしているのかを考えることは「何を」検索しているのかと同じように重要だ.
「良し,今から○○について調べモノをするぞ」と口に出してから,席に座ってキーボードを叩く,といったユーザはまれである.人が検索ボックスに対して何かを入力する時,その目的や理由は様々であり,ユーザ自身も言語化できていないことすらある.
このような観点は検索エンジンにとって重要だ.ユーザが「製品A」について検索した時,知りたいのは「それについてのカタログ情報」ではなく,使い方や関連するプロダクト,あるいはその製品について詳しいユーザからのアドバイスが欲しいのかもしれない.これまでのように文書とクエリの関連度をベースにランキングをするのは,ユーザからすると期待していない動作かもしれない.これはは古典的な情報検索の研究に比べて新しいフィールドだ.
方法論
In order to definitively know the underlying goal of every user
query, we would need to be able to ask the user about his or her
intentions. Clearly, this is not feasible in most cases. But can the
goal be determined simply by looking at the query itself, or is
more information required?
では,どうやれば「ユーザが何を考えて検索をしているのか」を定量的に推し量ることが出来るだろうか?
この研究チームはAltaVistaの検索エンジンで得られたクエリのデータを用い,これまでの彼らの経験とAltaVista内部での分析結果から,まずは手作業でユーザの検索行動の目的を100から200に分類し,実際のクエリを分類していくことで研究を進めた.
最初の見解として, ユーザは特定のWebサイトやクエリにまつわる情報を求めているわけではなく,ただオンラインのリソースを入手したいだけ であるケースが多いことが分かった.たとえば “Beatles Lyrics”** といったクエリは明らかに,ビートルズの楽曲の作詞家やビートルズファンのWebサイトを求めているわけではなく,ただビートルズの歌詞が知りたいだけだ.ここから,最初の100-200の分類(当初は *“finding a place in the world” といったクエリも含んでいた)は大きく改訂され,,resource searches と呼ぶ検索タイプに統合された.
このようなアプローチを繰り返していくうちに,ユーザの検索欲求の分類はしだいに階層化された.
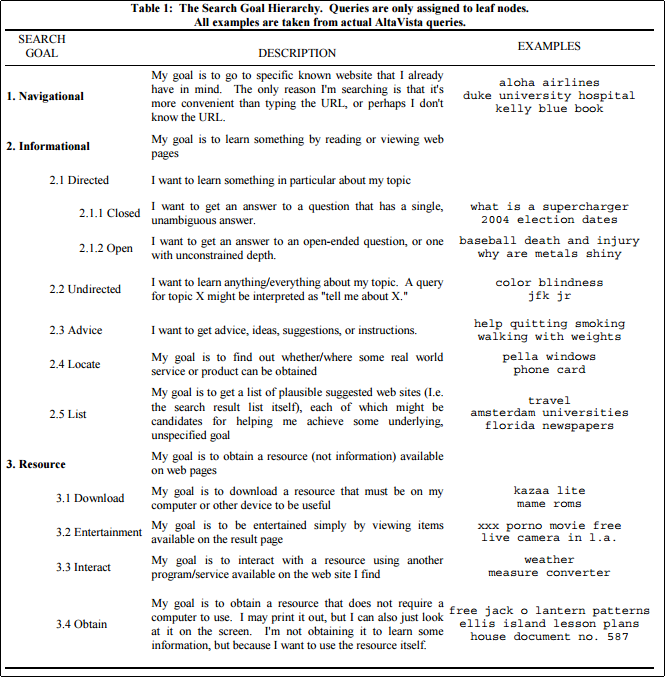
- Navigational: 既に存在を知っている特定のWebサイトへのリンクを表示してくれることを期待している.
- Googleの”I’m Feeling Lucky”機能を使うユーザなどは,殆どがこの目的意識であると考えられる.
- Informational: 特定のトピックについてより詳しく知ること,自分の今持っている知識と関連付けて,どこにあたる知識なのかを理解する道標を期待している.
- Resource: 特定のユーザとのチャットや,動画の再生,ソフトウェアのダウンロード等,何らかのリソースに触れることを期待している.
このようなクエリの分類が適切であるかどうかを判断するため,手作業でAltaVistaの検索ログから目的を分類するツールを作成した.勿論,検索を行ったユーザに「このクエリを入力した時,あなたは何を考えていましたか?」と聞くことができればそれに越したことはない.
が,ここでは以下の要素をもとに分類を行った:
- クエリそのもの
- 検索結果
- 検索結果の中でユーザがクリックしたもの
- 時間的に前後する他の検索クエリとそのクリック内容
これらの情報を用いて,目的が明らかである検索ログについては分類を行い,機械学習による自動分類器の教師データとした.
以下のような分類が手動でなされた:
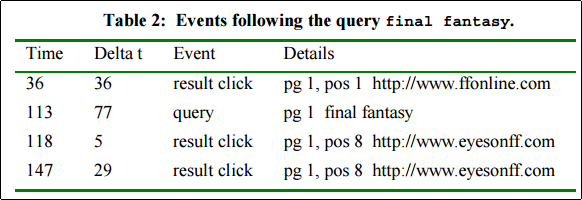
ユーザは Final Fantasy というクエリを入力している.ここで Navigational なクエリ,たとえばFinal Fantasyシリーズの最新作を購入したい,という欲求からきた検索クエリであれば,公式サイトへのリンクをすぐにクリックすると想定される.
が,実際にユーザがとった行動は,検索結果が表示された36秒後に,ffonline.com という非公式の攻略サイトの閲覧であった.また,それからしばらくして,このユーザは同じクエリで再度検索を行い,検索結果のランキング中でより下位にあった同種の非公式の攻略サイト eyesonff.com を訪れている.このことから,ユーザの目的は Infomartional , すなわち知識の獲得であったと断定する.
結果
AltaVistaの検索ログから無作為に抽出したある一日の500の検索ログを3セット(ただしアメリカ国内のサーバに存在したデータに限定する),用意し,この方法論を適用した結果が以下である.
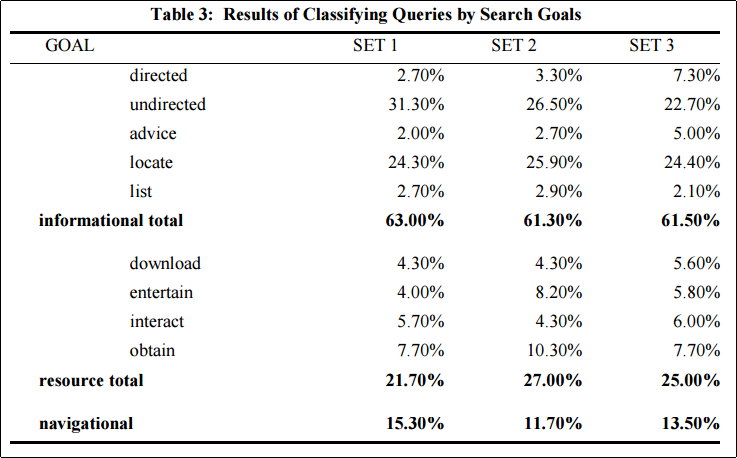
多くの検索クエリが Informational であることがわかる.これまでの情報検索研究が対象としてこなかった, undirected すなわち目的となるWebサイトが明確に存在しないような検索行動は3割近くを占めている.
興味深いのは,3つのサンプリングされた日付のSETごとに,カテゴリの相対分布が似通っていることだ.
また,SET 3では条件設定が少し異なり,ユーザのクリックログを加えて分類を行っているが,全体的な傾向は変化していない.
このあたりはさらなる研究が必要である.
In analyzing our results, we are aware of certain limitations that
may restrict the generalizability of our conclusions. One issue is
that we have no way of knowing conclusively whether the goal we
inferred for a query is in fact the user’s actual goal. In the future,
we would like to combine our work with user studies, including
qualitative data such as diary reports of user goals.
この研究から普遍的な結論を下すことは出来ないが,よりユーザの目的(Goal)を考慮した検索エンジンを検討する必要はある.
所感
We brainstormed a variety of goal possibilities, based on our own experiences…
と語られているように,この論文中における分類はかなりヒューリスティックであり,また分類も一部は手動で,力技に頼ったものである.
一方で,この論文の扱っている問題意識の目新しさからか,被引用数は多い.分類器を作ろうにも,正解となるクラスの定義からはじめなければいけないため,このようなアプローチとなるのもそれなりに理解できる.
この論文の二年後に,Communications of the ACMではExploratory Search特集が組まれた.
そこでは,ユーザの検索行動について以下の分類をしている.
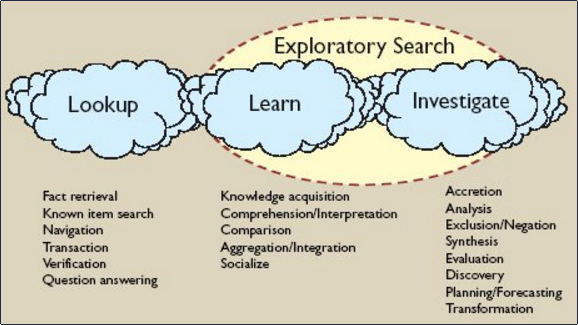
細分類としては “lookup”, “learn”, “investigate” と3つに分かれるが,大分類としてはこの論文と論旨は同じである.
Exploratory Searchの研究では,この論文でいう “informational” の検索行動についてより細分化して議論しているため,こちらも興味深い.
ただし,このようなExploratory Searchの研究は,ユーザの検索欲求を分類したうえで,検索欲求に対して適切なインタフェースやユーザ体験を提供する ことに焦点を当てている.そのためには,キーワード型の検索ボックスは廃して,新しいインタフェースを検討する.ICWSM2010の論文の例は以下である.
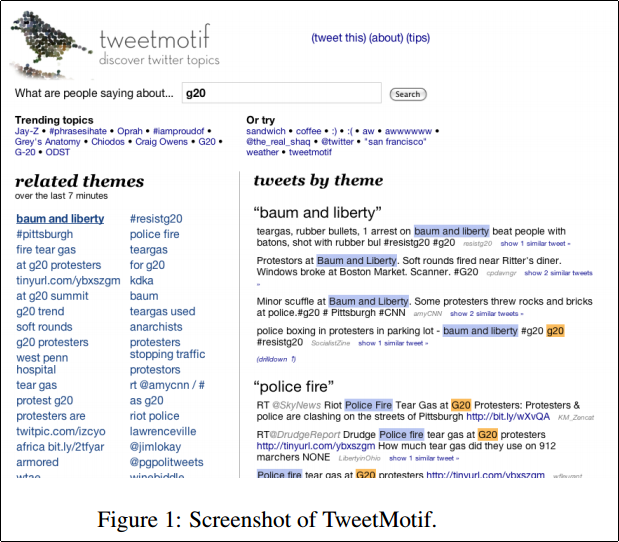
このように,navigational つまり探索的な検索を行うために,インタフェースの側から積極的にクエリ整形やクエリ生成の支援をするアプローチが取られている.
一方でこの論文が明らかにしたのは, キーワード型の検索エンジンにおいて,同じクエリが入力されていても,その目的(Goal)は異なる という点である.この問題意識について,インタフェースの側からユーザに寄り添い,たとえばかつてのディレクトリ型検索のような発展を遂げていくのか,それともキーワード型の「思いついたものは何でも入力できる」検索ボックスというインタフェースは変えずに,検索エンジン自体の仕組みを考えていくのか,というアプローチの違いが存在するわけである.
この種の問題意識を考える時,対象とするドメインを決定するかどうか,ということも非常に重要である.たとえば論文や書籍など,対象とする文書集合をある程度制約した場合,出版社や著者などのメタデータを検索エンジンに活用する,ということも当然考えられる.
Amazonの検索エンジンなどはその典型で,いわゆるファセット検索を用いて商品のカテゴリ(e.g. ブランド,価格,サイズ)を指定して絞り込みを行うことができる.
一方で,Googleのように,Web上に存在するテキストは何であれ検索できる,というセマンティクスをユーザに提供する場合,そうしたメタデータを用いることは非常に難しい.汎用的な知識集合の検索において,ユーザに見せられる潜在的なメタデータとは何か?ということから考えなくてはならないからだ.インタフェースの側から改善を行っていく,というアプローチは一気に難しくなる.