論文紹介: Building on Quicksand
書いた人: @nikezono
概要と紹介理由
ここまで,OCCやMVCCといった同時実行制御手法(Concurrency Control Algorithm)を紹介してきた.
これらの手法の理論的背景は古く,半世紀にもわたる歴史を持っている.
そして当時から変わらず共通する問題意識は,「並行アクセスを透過的に扱う」 ことにある.
シングルコア・シングルスレッド・シングルノードでの実行結果と全く等価な結果を,マルチコア・マルチスレッド・マルチノードでも,同じプログラムコードから得る―これが達成されれば,性能のためにコア数やノード数を増やすことに副作用はなくなる.
こうした問題意識は直列化可能性という理論として定式化され,前述したようにいくつものアルゴリズムや手法を生み出してきた.
しかし,アカデミアの努力とは裏腹に,現実はこの研究の成果を充分に享受しているとは言い難い状況にある.
先に取り上げたCOSTでは,無限のスケーラビリティなどというものは存在せず,マルチスレッドでの処理性能がシングルスレッドで直列実行した際の処理性能を上回るのは難しいということが示された.
また,Feral Concurrency Controlでは,現実にSerializable分離レベルは用いられていないであろうということと,それに変わる同時実行制御手法としてアプリケーションのレイヤでの一貫性の制御が普及していることをが示された.
今後のハードウェアの変化がどうあるかは分からないが,この十数年が分散システムの時代であったことは間違いないだろう.
そして直列化可能性の定理は分散システムの時代に適合しなかったというのが現実である.
同時実行制御の大敵であったディスクI/Oの遅延に加えて,ネットワークI/Oの遅延や,容易に分断しうるネットワーク,常に故障が起こりうるクラスタ,というものを考慮した時に,既存の直列化可能性の定理をそのまま当てはめてシステムを構築することはもはや難しくなった.
そのような時代の変化に対して,一貫性と信頼性を両立したシステムとはどうあるべきか,という指針を示したのがCIDR2009のこの論文である.
“Building on Quicksand” というタイトルは日本語で言えば「砂上の楼閣」に当たるだろうか.旧来の直列化可能性という堅牢な基盤の上でアプリケーションを展開するアプローチとは異なり,不確かなコンポーネントの組み合わせで高信頼のシステムを作り上げることに主眼を置いている.
Reference
Pat Helland, David Campbell:
Building on Quicksand. CIDR 2009
http://www-db.cs.wisc.edu/cidr/cidr2009/Paper_133.pdf
Abstract
Reliable systems have always been built out of unreliable components.
ECCメモリやディスクのミラーリングなど,システムを構成するコンポーネントの信頼性は,かつては透過的に扱えるものだった.
しかし今,ひとつのシステムを構成するコンポーネントはあまりにも多く,複雑なトポロジーを成し,階層化している.
システム設計においては,ひとつのディスクの故障とバックアップが問題であったものが,今ではデータセンターレベルのネットワーク遅延や寸断を考慮しなければならない.
このような障害時にリモートのバックアップからリカバリを行う,という旧来のスタイルを適用することは難しい.
全ての更新をリモートに同期して反映させ,バックアップも行う,というのはあまりに通信コストが大きすぎる.
ここから導かれるのはよりリラックスしたフォールトトレラントのモデルである.
たとえば,master/slaveモデルを取り,masterの更新をslaveに同期する 前に ,masterがユーザにレスポンスを返してしまうとする.
いわゆる非同期レプリケーションである.
こうすればバックアップに通信する遅延をユーザから隠蔽できる.
が,このようなやり方には二つの含意がある:
1) Everything promised by the primary is probabilistic. There is
always a chance that an untimely failure shortly after the
promise results in a backup proceeding without knowledge of
the commitment. Hence, nothing is guaranteed!
バックアップが確実に取られるという保証はわずかなネットワーク瞬断で失われる.
2) Applications must ensure eventual consistency [20]. Since
work may be stuck in the primary after a failure and reappear
later, the processing order for work cannot be guaranteed.
レプリケーションの内容が必ず最新のものであるという保証もなくなる.これは結果整合性の上でアプリケーションを作ることを要求される.
ミドルウェアやフレームワークを開発するエンジニアやアーキテクトは,この性能と耐障害性とアプリケーションの開発の容易さという3つの要因を鼎立させるために腐心している.その中で生まれたデザインパターンをこの論文では分類している.
透過性と冪等性
前置きとして,この論文中では,フォールトトレラントなシステムを論ずるに当たり,故障モデルの定義として,Fail Fastモデルを置いている.すなわち,あらゆる故障は即座に他のノードに通知される.また,ビザンチン故障は一切考慮しない.
さて,フォールトトレラントなシステムと聞いて我々が理想とするのはブラックボックス化したシステムである.
何がしかの手段でAPI(e.g. REST/SOAP)を提供しており,そのAPIを叩くと,レスポンスが帰ってくる.
この当たり前の挙動の原則が,ノード数がどれだけ増えてもどのような障害があっても 透過的に 維持されることが理想的だ.
これをどう実装するかというと,古典的なやり方としては,あるノードに届いたリクエストはなるべくそこで処理をして,
一定時間が過ぎてもレスポンスを返さなければ,タイムアウトとみなして他のノードにリクエストをし直す,というやり方がある.
このアプローチはやはり含意がある. ユーザから見て一回しか発行していないはずの同じリクエストが,複数のノードで処理されうる という点だ.
これによって生じる問題を防ぐには,開発者が 冪等なアルゴリズム でアプリケーションを記述するか,他のhackを行う必要がある.たとえば,ユーザから届く各リクエストにはユニークなIDを生成し,ミドルウェア側が 全システムで一度きりしか実行しない(exactly once)こと を保証する,とか.
ユーザが冪等なアルゴリズムを書くことを強制すれば,ミドルウェア側の制約を少し緩められる.ミドルウェアは 全システムで一回以上実行する(at least once)こと を保証してくれれば,アプリの動作は期待した通りのものとなるだろう.
冪等なアルゴリズムによってシステムを構成した際,よく使われるデザインパターンは, 冪等なアルゴリズムの組み合わせでシステムを構成し,アルゴリズム間の状態を保存する というアプローチだ.
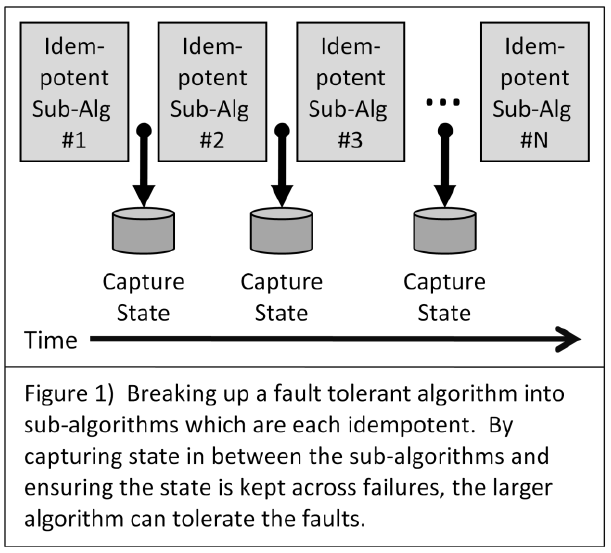
you can imagine stepping across a river from rock to rock,
always keeping one foot on solid ground.
It is important to realize this provides a linear sequence of steps
marching forward through the work.
このとき,各サブアルゴリズムの冪等性について,特別にアプリケーション開発者に何かを強いることはしなくてもよい.
ひとまとめの処理の系列として ACIDトランザクション を用いて実行することで冪等性を容易に担保できる.
トランザクションのACID特性,特にAtomicityは,処理がいつ中断されても,必ず実行されたか全くされていないか,という二つのstateのどちらかにリカバリできることを保証している.この性質を用いて,複数のトランザクションと中間状態を保持するstateというセマンティクスを開発者に与える ことで,フォールトトレラントなシステムを 透過的に 構築できる.
透過性の進化
この論文では,名だたるトランザクション研究者が在籍していたDB企業であるTandem社のTandem NonStopというシステムの進化の歴史を追いながら,透過性とフォールトトレラントについて考察している.
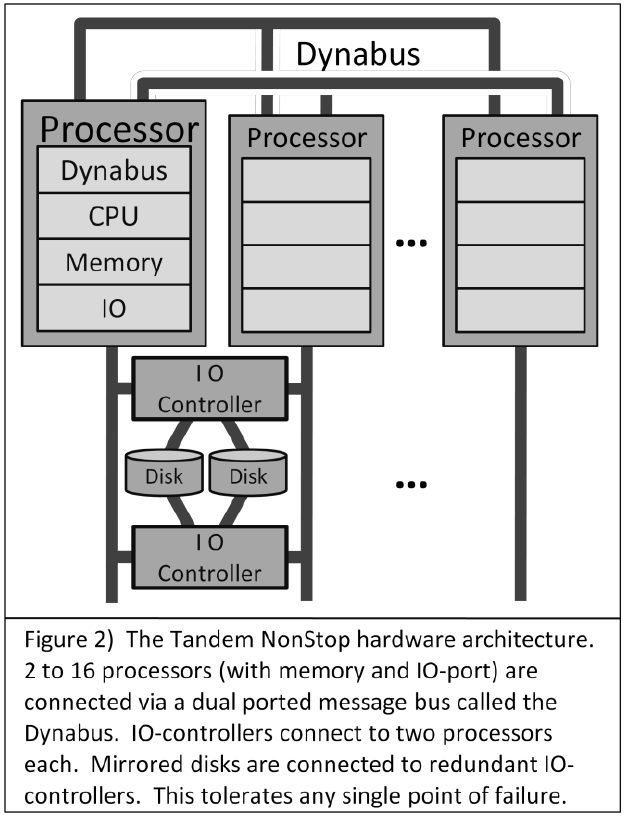
Tandem Nonstopはタンデム社の開発したshared-nothingアーキテクチャを取るデータベースである.
マルチプロセッサでの動作が可能であり,各プロセッサはそれぞれにCPU/メモリ/IOコントローラを持ち,共有バスで接続されている.
I/Oコントローラは2ポートを持っているため,複数のプロセッサが共有することもある.
このハードウェア構成にGuardian OSを組み合わせたものがTandem Nonstopである.
Tandem NonStop circa 1984
1984年のTandem NonStopはあらゆるコンポーネントを冗長化し,Single Point of Failureをシステムから取り除いていた.
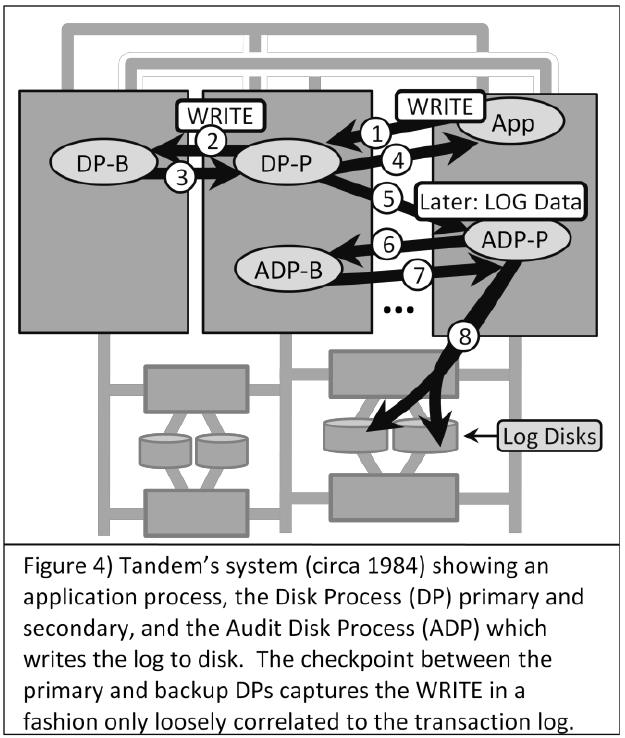
各トランザクションは一つのプロセッサ上で実行され, READS WRITES のメッセージをディスクプロセス(DP)に送付する.
ディスクプロセスはログを書き出し,データを書き込む.各 WRITES 命令ごとにチェックポイントが実行され,リカバリ可能とする.
トランザクションがコミットされた時,各DPが Audit Disk Process という中央集権的なディスク管理プロセスにログがACIDに違反せず書き出し可能かどうかを問い合わせる.
この設計は先ほど見た「冪等なサブアルゴリズムとstateのセマンティクス」と同等のものである. 各WRITES命令の結果はstateして保存され,WRITES命令はアトミックなサブトランザクションとして扱える.故障による障害範囲は一つのプロセッサ上の一つのWRITES命令に留まる.
Tandem NonStop circa 1986
1986年のTandem NonStopはディスクプロセス(DP)を刷新し, DP2 と呼ばれるコンポーネントを備えたものと鳴った.
DP2はチェックポイントについての変更が特にドラスティックだった.
チェックポイントログとトランザクションログは全く同一のものとなり,WRITES命令ごとに書き出されるログは,トランザクションのDurabilityのためにも,チェックポイントのためにも用いられた.(2017年の今から見れば,当たり前のアプローチではある.)
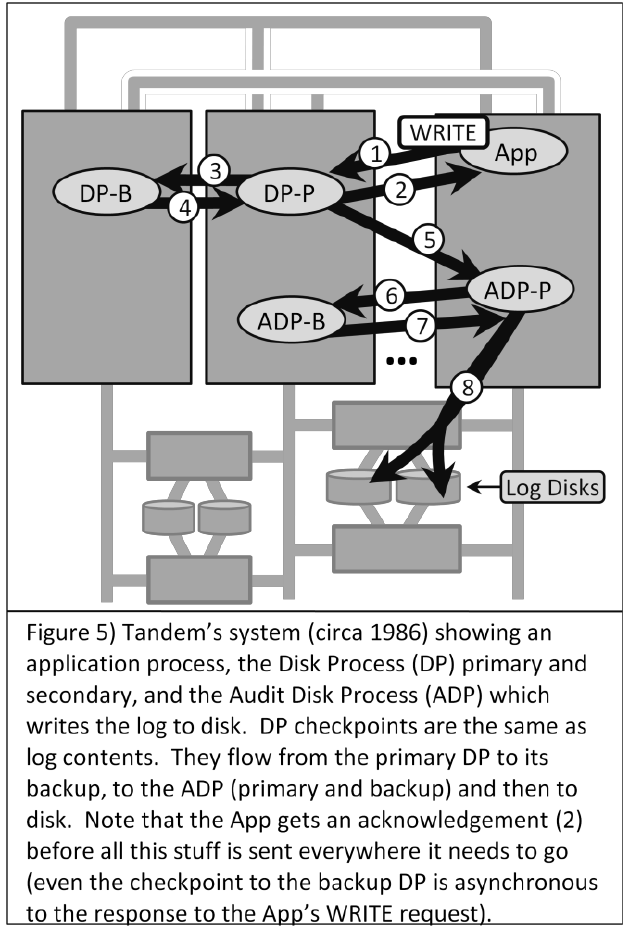
各トランザクションはWRITES命令を,DP2にログを送付した時点で終了できる.
こうすると,DP2がログを実際にディスクに書き出しているかどうかは各トランザクションからはわからない ため,他のトランザクションが読んでいる値は実は永続化されていない値かもしれない.このため,(DPの故障などにより)あるトランザクションのWRITESがユーザには成功を返していても,実際は失敗しているというケースが起こりうるようになる.当然,このWRITESの結果をメモリ上から読んでしまったトランザクションは,存在してはいけない値を読んでいるとみなせる.いわゆる回復不可能なトランザクションの挙動である.
Tandem NonStop 1986では,DP2ないしディスクが故障した際には,関連するDP2上で走っていた全てのトランザクションをアボートさせる.
これにWrite Ahead Log(WAL)のアプローチを組み合わせることによって,「コミットされたトランザクションの内容は必ず書きだされており」,「不正な値を読んだトランザクションはアボートする」という原則を守ることができる.
この変更は利点も欠点もあった.ログバッファのフォーマットは一元化され,CPUコストが削減された.
WRITES命令があっても,ログを書き出す前にそのレコードのREADSを許すことから,レイテンシが削減された.
また,いわゆるグループコミットのような最適化が可能となり,IOPSやI/O帯域も効率的に使用出来るようになった.
しかしながら,この変更によって,「DP故障によってあるトランザクションが障害を起こした時,他のトランザクションもアボートさせる」という点で,障害耐性の点ではむしろ1984年の設計より複雑になってしまった.1984年の設計では,あらゆる障害における障害範囲(Failure Boundary)は
そのDPが実行しているWRITES命令一つに限っていた. 1986年の設計における冪等なアルゴリズムにあたるものはトランザクションであり,故障範囲は最大でアプリケーション全体にあたることとなった.
この設計の変化は,トランザクションが アボートする という基本的なセマンティクスを提供することによって受け入れられるものとなった.
WRITES が失敗したとか,あるトランザクションが途中で実行を止められた,という状態遷移をユーザに意識させるのは困難だが,
理由はどうあれ(デッドロックかもしれないし,故障かもしれないし,タイムアウトかもしれないが,とにかく何であれ)アボートした という述語に状態を集約することで,ユーザから見た透過性を維持していた.
非同期書込みに関する議論
この論文では,Tandem NonStopの1984から1986における変化を典型として,「ユーザから来たリクエストが,確実にバックアップまで可能になったことが保証される前に,ユーザにackを返してしまうこと(Asynchrony)は何を意味するか?」について検討している.
Log Shippingは多くの読者が知っているテクニックだろう.データベースの変更内容をレプリケーションするために,データそのものではなくログ(論理ログと物理ログがあるが,ここでは区別しない)をバックアップに受け渡すアプローチである. ログがバックアップや参照用のバックアップに受け渡され,データの変更内容の同期が完了した時点でユーザにコミットを返し,その間にもし障害が起こった際はトランザクションをアボートさせれば,システム全体を同期させることができる.
ログをバックアップに受け渡し,その反映を待たずにユーザにコミットを返却する非同期Log Shippingは,明らかに障害時に問題が起きうる.たとえばmaster/slave構成でmasterが障害を起こした際,slaveに適用されていないがmasterはコミットを返してしまったデータ は当然,存在しうる.このデータは永久にロストしてしまう.これはつまり フォールトトレランスを透過的に扱えていない ということであり,アプリケーションエンジニアはそれを意識してコーディングする必要がある,ということだ.
だがこうした選択肢はRedisやPostgreSQLでも提供されている・
ユーザにコミットを返却しなければ,データセンター内部では非同期レプリケーションを行い,過半数の合意をもってデータセンター内での同期が取れたとみなし,さらに地理分散したデータセンター間での同期を同様に行う・・・という様に,ユーザに対する透過性を維持したまま非同期レプリケーションの恩恵を得ていくことはできる.この場合ミドルウェア側は分散合意の議論を汲む必要がある.が,このようなアプローチはユーザに対するレイテンシの影響が際限なく増加していく.データセンタがまるごと災害によって失われた際に,故障によるデータロストの可能性が起きるというリスクを許容すれば,ユーザにコミットをより早く返却することができる.この議論は階層的である.
今度は同期する範囲をラックに限定して,あるノードが故障してもラック全体が故障しなければ...という風にまた細分化できる.
このようにリスクと性能のトレードオフを取っていくことができる.
抽象化をやりなおそう
これまで見てきたモデルは典型的な直列化可能性をベースにしている.
すなわち,あらゆるシステムをREADSとWRITESの処理の系列を生成するものとみなし,「単一のシステム上で順番に実行した際の結果と等価であるか」 を検証して異常を判断していた.
ログは当然ひとつのファイルに集約されるし,そのログをリプレイすれば処理全体をリプレイ可能であるというモデルだった.この抽象化は確かに分散システムに対して 透過的 である.
しかし,先に見たように,世の中でもはや当たり前のように使われる非同期レプリケーションですら,厳格に実行するにはオーバヘッドが高すぎる.とはいえ,アプリケーションを書く開発者に対して,耐障害性を意識させるということはできれば避けたい.そこで,ここで新しい抽象化のモデルを考えてみる.
まず,新しい抽象化では,WRITES READS処理の系列は二度とリプレイできないことを前提とおく.そしていくらでも系列はリオーダされうるものと考える.つまりこれは,Figure 2にあるようなstateを知る方法が全くないということを意味する.また,WRITES READS というアトミックな処理の単位すらも考え直さなければならない.
The deeper observation is that two things are coupled:
1) The change from synchronous checkpointing to asynchronous to save latency, and
2) The loss of a notion of an authoritative truth.
これは可用性(Availability)と一貫性(Consistency)のトレードオフが存在することを意味する.
このような原則から導かれるのは,アプリケーションロジックが 冪等性と可換性があり,確率的に実行される モデルをどれだけ許容できるかを考えることが重要である,ということである.
- 冪等性: 処理が何回実行されても同じ結果であること
- 可換性: 2つの処理があった場合,どちらが先に起こったとしても矛盾がないこと
- 確率的な実行: ユーザにコミットを返したはずの処理が系全体に反映されないこともありうるということ.
Locally clear a check if the face value is less than $10,000.
If it exceeds $10,000, double check with all the replicas to
make sure it clears.
たとえば,ATMの現金引き出し等は上限額が設定されている.これは,一つ一つの引き出しリクエストに対して,全ATM同士の同期を取るというのはあまりにもコストがかかりすぎるからである.
上限額を設定することで,それぞれのノードでは同時に預金引き出しを実行可能であるが,障害時や異常時の損害額は制限できる.
Schedule the shipment of a “Harry Potter” book based on a
local opinion of the inventory. In contrast, the one and only
one Gutenberg bible requires strict coordination!
一方で,グーテンベルク聖書の輸送オペレーションなどはハリー・ポッターシリーズの発送とは異なり,厳格に同期する必要がある.
確率的に実行されるアプリケーションの上で,どのような異常が発生し,どのようなバグが起きるのかは全くわからない.
READS WRITESの処理の系列でアプリケーションをモデリングすることを諦め,ビジネスロジックに向き合うという設計を取っている以上,
起きた異常がどのような類型にあたるのかもやはりわからない.
そこで著者が提言しているのは以下である.
- Send the problem to a human (via email or something else),
- If that’s too expensive, write some business specific software
to reduce the probability that a human needs to be involved
結局のところ,ビジネスロジックとビジネス要件,運用上の制約は常に移り変わっていく.運用しながらそのトレードオフの最適解をとらえていくしかない,ということだろうか.
Zen And Art of Eventual Consistency
前述した「運用しながら〜」の論理は,一般化して以下のモデルとできる.著者Pat Hellandの提言するモデルでは,
あらゆるコンピュータの計算処理は3つの分類(Memories, Guesses, Apologies)に落ちる・この分類モデルを分散システムに適用すると,
- Memories: 記憶すること.分散システムにおいては,ローカルの変更は同じマシンにおいては同じ結果を返してくれることを期待する.例えば,オフラインのユーザがスマートフォン上で実行した結果は,そのスマートフォンの上では保持されているとよい.
- Guesses: ローカルの変更は必ず間違いうる.リモートや系全体との整合性を取った結果としてその処理は棄却されうる.
- Apologies: 間違った処理の結果は,補償されなければならない.分散システムにおいては,
Guessesの結果は誤りを含みうるのだから,そのデータを処理していたノードを棄却することをアプリケーション上どういう扱いにするかを考えなければならない.
この3つを自分のアプリケーションやシステムがどこでどう実現しており,どのトレードオフを取っているかを考えることが重要である.
例えば,論文ではAmazon DynamoDBによるショッピングカートの例と,空港の座席予約の例を挙げている.
Amazonでは,カートに商品を追加する処理はグローバルなロックを獲得しない.商品をカートに追加する,ということは,現実のアナロジーに即して言えば,誰かが棚から商品を取ったのだから,データベースの在庫テーブルをロックし,特定のレコードを削除し,ロックを開放することにマッピングできる.が,Amazonはそうしていない.ただ在庫テーブルの変化をMemory するのみである.これは結果として,複数人が同じ在庫をカートに追加し,どちらかが商品を買えなくなる可能性があることを意味する.が,在庫テーブルの更新ロックを取ることによる他のユーザへの影響を抑えるために,Amazonはこの選択を行っている.
また,空港の座席予約においても,同様のアプローチが取られることがある.実際以上の座席数を予約してしまう現象はオーバーブッキングとして知られている.これもまた,システムの負荷を下げ,一貫性を弱める代わりに,ユーザの利便性を向上させるアプローチである.
そしてここには,障害時(過剰予約時)には代替便を用意するという Apologies が存在するわけである.
フォールトトレランスの未来と開発者の負荷
さて,1984年のTandem Nonstopの時代から現代に至るまでの意識の変化を見て,
アプリケーションエンジニアにかかる負担も増している.
かつては,シングルノードで動作するREAD WRITES命令の系列,ならびにそれを拡大したトランザクションというセマンティクスを扱うだけで, 透過的に分散システムにおいても一貫性を保つことができた.
現在の,地理分散した,いつでもネットワーク分断しうる巨大な系を扱うシステムを扱うエンジニアは,自分の書いているアプリケーションロジックが冪等か?可換的か?確率的に実行されてもかまわないか?という観点を常に持つ必要がある.また,各ロジックがMemories, Guesses, Apologies のどこに当てはまるのか,どのような役割を果たしているのか,を意識することが重要となる.
What are the operations in play for various applications?
When are they commutative? What practices make the operations
idempotent?
Are there different solutions that are recast syntactically in different environments? Is there a taxonomy of patterns into which the various solutions can be cast?
Our forefathers were VERY smart and were dealing with loosely coupled systems to implement their businesses.
They knit the loosely-coupled systems together with messages, telegrams, letters, and the postal system.
To cope, they needed reorderable operations.
Sometimes, the work was requested twice and this required protocols to implement idempotence.
How were these schemes used to run a railroad and build a Model-T?
Are these patterns still there waiting for us to use in our distributed systems?
所感
アプリケーションが必要とするスループットやレイテンシは右肩上がりに上昇しており,必要とする計算リソースもやはり指数関数的に向上している.
一方で,現実的にアプリケーションの性能を稼ぎ出すには,ムーアの法則や電力の限界から,必然的にスケールアップよりスケールアウトの方向に倒れていく,というのがここ十数年の流れだったと私は思う.
この流れがどのような制約をアプリケーションエンジニアに強いたのか,ということを過去の記事12で取り上げた.
この論文はそのモデリングについてより抽象化した語っているものであり,ここで語られていた考察はなかなか興味深いものだ.
一方で,この論文の6年後に語られたFeral Concurrency Controlは一歩進んだ議論をしている.求められるのアプリケーションエンジニアの意識の変革ではなく,ユーザに与える共有データ操作の透過的なセマンティクスであるという点を明確にしており,そのヒントとしてORマッパーに着目している.
私もこの論文の議論は刺激的ではあったが,より将来のシステムについての議論という点では不足していると感じる.アプリケーションのビジネスロジックをどう分散システムに落とし込むか,という点において,透過性を捨てて行き着く先がこのようなカオスというのは,なんともツラい話だ.
現代のミドルウェアエンジニアの責務はここにあると思う.