論文紹介: When Experts Agree: Using Non-Affiliated Experts to Rank Popular Topics
書いた人: @ytanaka
概要と紹介理由
今回は2007年のGoogleNewsの論文を紹介するつもりだったのだが、本論文の著者でありGoogleNewsの創始者でもあるKrishna Bharat氏と交流できる機会を得たので、この機会にBharat氏の論文を読んでみることにした。
本論文で提案されているHilltopアルゴリズムは、発表の2年後の2003年にGoogleに取り入れられることとなるアルゴリズムである[1]。
提案背景として、当時からすでにユーザは通常検索結果の上位10~20件程度しか閲覧しないという研究結果が知られていたものの、その上位がサブドメインを使った膨大なサイト群からのキーワードリンクスパムになどを使った手法に汚染され、ウェブスパムが蔓延している状況だったことがある[2]。
またPageRankはあるキーワードに対してのスコアでないため、入力されたクエリに対しての関連性を検索スコアに取り入れることができていなかった。そのためスパムの影響を排除し、かつ入力されたクエリに対する関連性を加味したスコアリング手法が求められていた。
Hilltopアルゴリズムは、スパムをルールベースで排除した上で、他ページへのリンクを一定数以上持つ「Expertなページ」をまず見つけ、次に各キーワードに関連したExpertなページから多くリンクされている「authorityなページ」を見つけ出すというものである。
最終的な実装の結果として、既存の主要な商業検索エンジンを上回るパフォーマンスを誇ったことが論文中で報告されている。
ACM Refs
Krishna Bharat and George A. Mihaila. 2001.
When experts agree: using non-affiliated experts to rank popular topics.
In Proceedings of the 10th international conference on World Wide Web (WWW '01). ACM, New York, NY, USA, 597-602.
DOI=http://dx.doi.org/10.1145/371920.372162
WebPageのランキング手法
2001年当時のランキング手法は以下の三つに大きく分けられた。
- 人手によるランキング
- 利用情報によるランキング
- グラフ理論を用いたランキング
それぞれの特徴を述べると、人手によるランキングはYahooのディレクトリ型エンジンのように人間がカテゴリに分類するもので、膨大なWebページに対して適用は難しく主観によるためその分類が適切かどうかの判断が難しいという問題がある。
利用情報によるランキングはWebページを何秒みたかといった情報を加味するものだが、膨大なページ量に対して、ユーザが入力するクエリと閲覧するページは限られているためうまくいかない。またスパムの影響を受けやすい。例としてDirectHitというサービスが紹介されていた。
最後のグラフ理論を用いたランキング手法が、Webページ間のリンク構造を利用したもので、PageRankなどの現在使われている手法である。
PageRankはあるキーワードに対してのスコアでなく、ウェブ(リンク構造)全体からみた重要度を推し量るものであった(query-independentなアプローチ)。
しかし検索エンジンではユーザが入力したクエリに対して最も参考になるページを返す必要がある(query-dependentなアプローチ)。
そこでTopic distillationというクエリに対して関連がないページを除き、関連するページのみでスコアを出すというアプローチが提案されていた。しかしこの方法はリアルタイムに計算を行うことが難しく、即時に検索結果を返す必要がある実際の検索への適用は難しかった。
Hilltop Algorithm Overview
以上のような背景から、スパムを取り除いた上で入力されたクエリに対して最も関連のあるページを、現実的な速度でスコアリング可能なアルゴリズムの必要性が生まれた。
それを解決する目的で提案されたのが本論文のHilltopアルゴリズムである。
このアルゴリズムは他ページへのリンクを一定以上持つExpertなページをまず見つけ、各キーワードごとに、Expertなページから多くリンクされている「authorityな」ページを見つけ出すというものである。
具体的には以下のようなステップからなる
- スパムページを取り除く
- ExpertなページをIndexingする
- ユーザの入力したクエリと関連するExpertページをみつける
- Expertページから多くリンクされ、かつ入力クエリと関連度が高いページをみつける
最終的に4のステップで各Webページはスコアリングされ、上位N件がユーザにリストで返るという流れになる。
Detecting Host Affiliation
まずスパムの検知方法だがこれは今からみるとかなり力技なルールベースのアプローチである。以下のようなルールを設定し、どちらかに合致するものはアフィリエイト(スパム)とみなすというもの。
- IPアドレスの第三オクセット目まで同一であるようなホストからのリンク
- FQDNの中からgenericな部分を取り除いたキーワード(adc.comとabc.jpならabc)が同じであるページからのリンク
IPアドレスの部分は当時の事情だろうか。今はAWSなどのクラウドインフラがあるのでこのようなアプローチは使えないだろう。ただこういうアプローチも泥臭いがなかなか興味深い。
Indexing the Expert
クロールされたWebページのデータから、1. out-degreeが5以上のもの 2. 前述したスパムホストを排除したもの、の両方を満たすものをこの論文ではExpertなページとみなしている。スレッショルドがin-degreeでなくout-degreeなのは次のステップでauthorityなページを見つけるためだと思われる。
さてこれらのExpertなページは、URLとtitleやheadタグの内容、anchor textからキーフレーズを抽出し転置インデックスによってIndexingされる。
つまりキーワード(トピック)ごとにExpertなページ群が作成されることになる。
Query Processing
検索結果を返すために、ユーザが入力したクエリに対応するExpertページ(これらはExpert ScoreによってSortされる)上位200件がまず算出される。
次にExpertページが指し示すページ群から、より多くリンクされ、入力クエリと関連性が高いようなページが抽出され、ユーザに返される。
ExpertScoreとTargetScore
ExpertScoreはユーザの入力するクエリが、Title(16point), Headタグ(6point), anchorテキスト(1point)に含まれているかどうかによって算出される(各pointが加算される)。2つ以上クエリが入力された場合は最初に入力された方のクエリとの関連度が重視される実装になっている。
要はクエリとの関連度が高ければ高くなるスコアであるとみていい。
TargetScoreは、少なくとも2つ以上のExpertページからリンクされたページ(これを候補ページとここでは名称する)を対象に
- EdgeScore = ExpertScore * (候補ページの中に入力クエリが含まれていれば1, そうでないなら0)
- 1の式で算出されるEdgeScoreをすべての候補ページに対して行い、それらの値を合計する
というような過程を経て算出される。
要はExpertScoreが高いページから多くリンクされていて、かつ入力クエリに関連したページのスコアが高くなるアルゴリズムであるということである。
最終的にTargetScoreの上位がユーザに返される。
評価
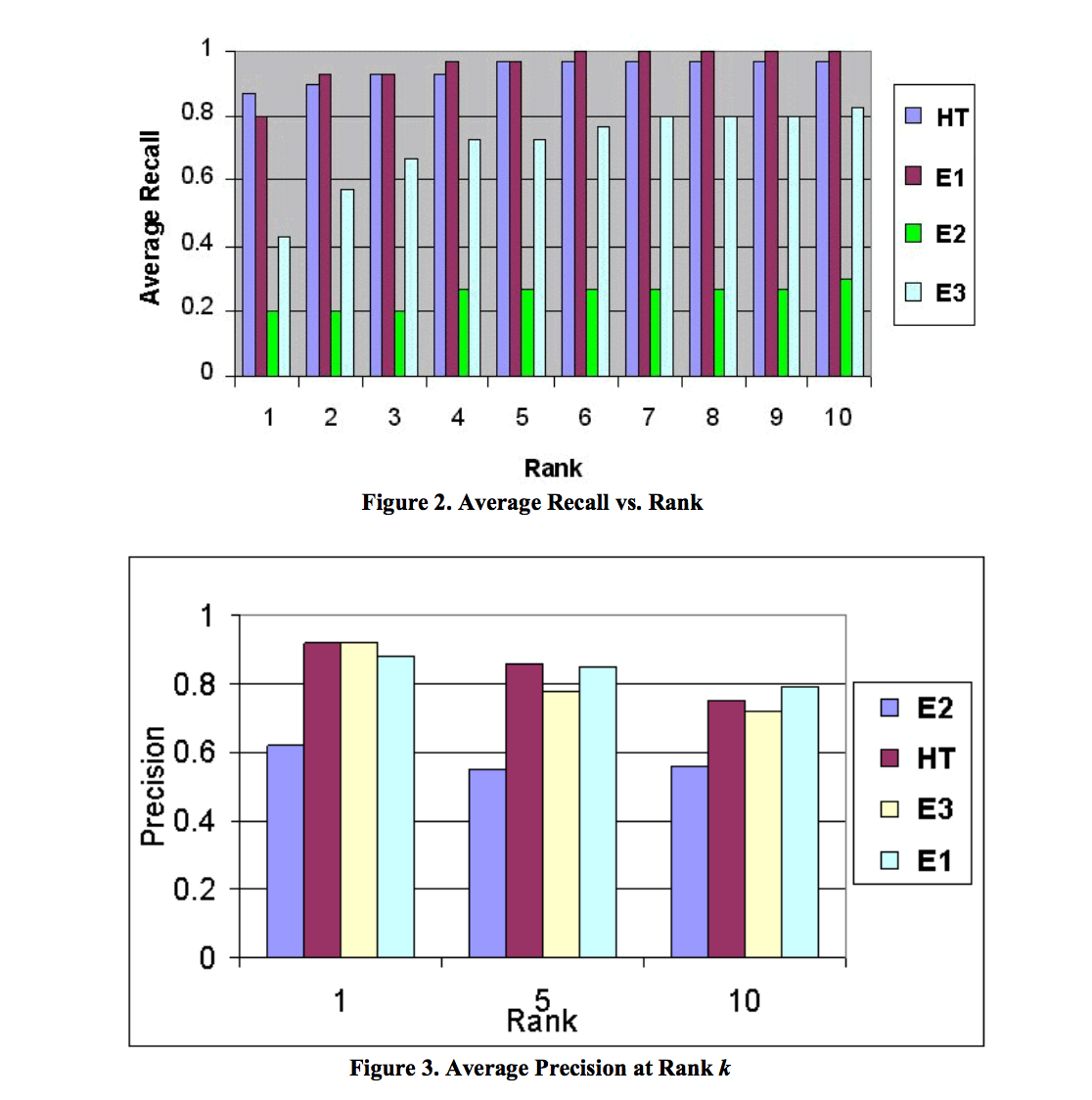
評価は論文で提案されたHilltopアルゴリズムと、 当時の検索エンジンであるAltaVista, DirectHit, Googleとの比較実験である。結果としては以下のように特にRank上位においてのRecallとPrecision性能差が見られる。E1との性能差が切迫しているところをみるとこれがGoogleだろうか(論文ではE1が何かは明記されていない)。
感想
さて実装はなかなか力技ではあったが、私的にはこの論文の問題意識と解決手法の方向性は現在にも通用すると思っている。
リンク構造を使ってページを評価する際に、評価者である側と評価を受ける側を分けるというのは現実世界をアナロジーに使ってもピンとくるものがあるし、評価のExpertとExpertからの評価を受けるものが権威(authority)を持つというのも面白い。
リンク解析のpreprocessing時にこのような役割分けをしておくのは常識なのかもしれないが、意外と発想としては他にも転用できそうな雰囲気を感じる。似たようなアプローチとしてTrustRank[3]がある。
これはスパムがリンクを張るのはスパムが多く、信頼できるサイトが張るリンクは信頼できるという傾向をリンク解析に取り入れた手法である。
今では当たり前に使っているGoogleのPageRankのアイデアも、辿っていくとこのような形で少しずつ拡張されていったというのは新鮮だし、その過程を振り返ることもときには重要であるとわかったのは収穫だった。
リンク
[1] https://en.wikipedia.org/wiki/Hilltop_algorithm
[2] http://www.sem-r.com/news-2013/20131220143954.html
[3] https://en.wikipedia.org/wiki/TrustRank